Convolution 소개
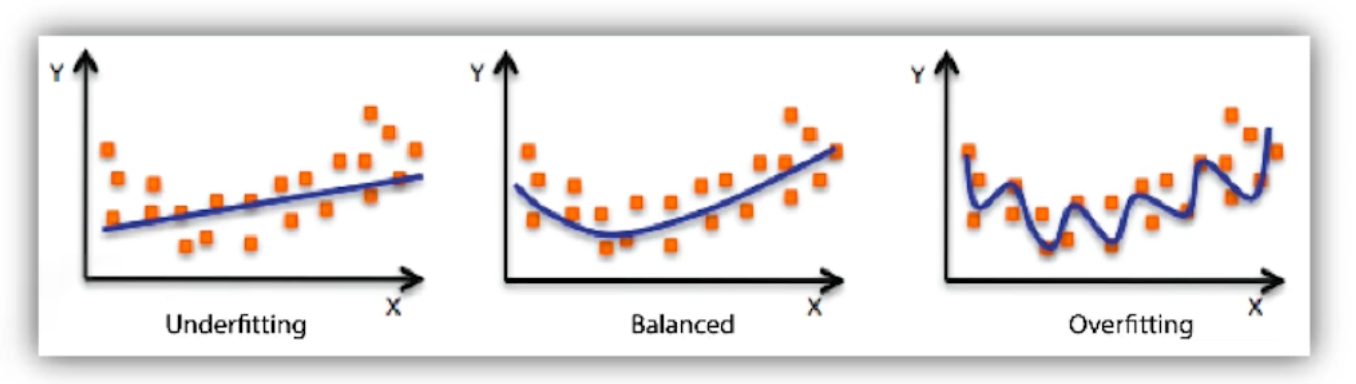
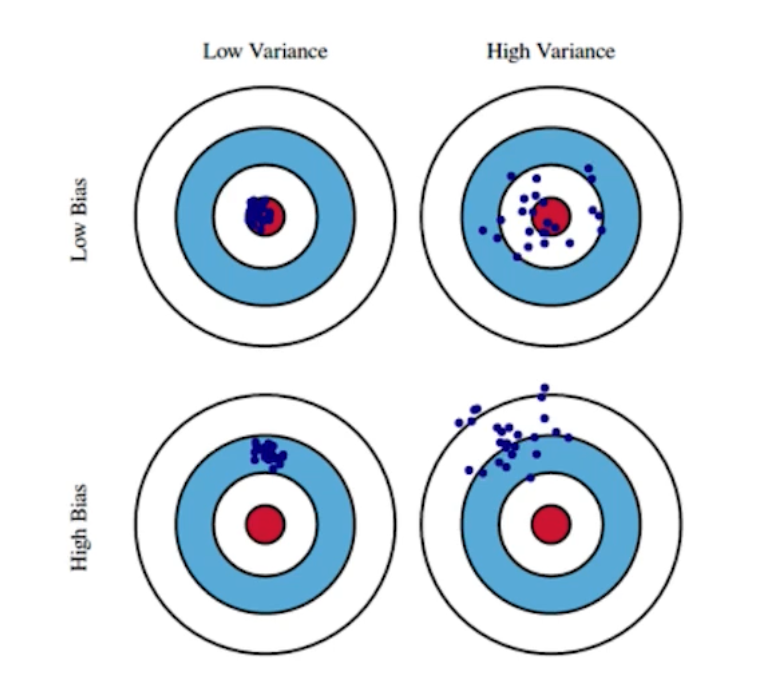
파라미터 수 손으로 직접 계산해보기
알렉스넷의 파라미터 수 구하기
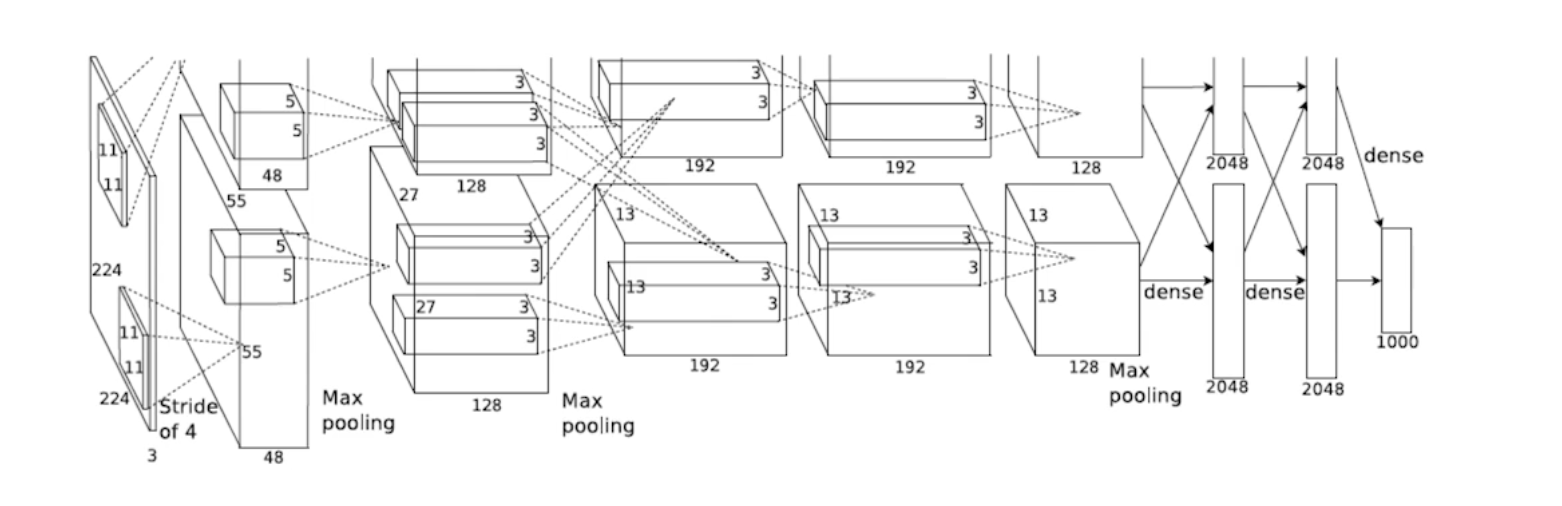
input = 224 224 3
filter = 11 11 3
fisrt param = $11113482 ~= 35k$
Modern CNN
AlexNet
네트워크가 두 개로 나뉘어져 있다. 당시 GPU가 부족했기 때문임. 두 장의 GPU로 학습하고 합쳤다. 인풋에 $11 * 11$ 필터를 사용했는데, 파라미터 관점에서 좋진 않다. 상대적으로 많은 파라미터가 필요하기 때문. 이후 5개의 Convolution 레이어와 3개의 Dense 레이어를 사용한다. 최근 200-300개 네트워크를 가진 신경망에 비하면 Light한 편이다.
Key Ideas
- Rectified Linear Unit(ReLU) 활성화 함수를 사용했다. $ReLU = max(0, x)$
- 리니어 모델이 갖는 좋은 성질들을 가질 수 있게 한다.
- 리니어 모델들의 성질을 가지고 있기 때문에 학습하는 SGD나 Gradient Descent로 학습을 용이하게 한다.
- 활성화함수를 사용할 때 이전에 많이 활용하던 Sigmoid나 tanh 같은 경우 값이 커지면 슬로프가 줄어들게 된다. 슬로프가 결국 기울기니까, 뉴런의 값이 많이 크면(0에서 벗어나면) Gradient Slope는 0에 가까워진다. 이 때 Vanishing Gradient 문제가 발생할 수 있는데, ReLU를 사용하면 해당 문제를 해소할 수 있음
- GPU Implementation (2 GPUs)
- Local Response Normalization(어떠한 입력 공간에서 Response가 많이 나오는 부분을 죽이는 것임. 최근엔 많이 사용되지 않음), Overlapping pooling
- Data Augmentation
- Dropout