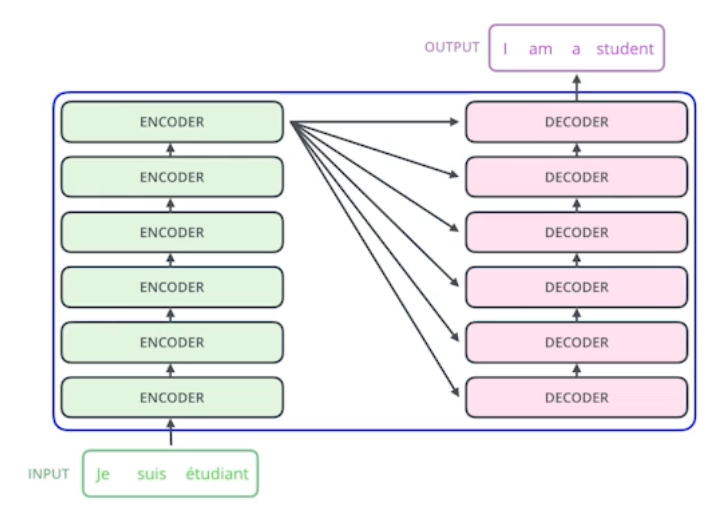
프로그래머로 산다는 것 - 라이엇 게임즈 유석문 CTO
1. 개발자???
2013 문화체육관광부 우수학술도서 - 프로그래머로 산다는 것(황상철, 하호진, 이상민, 김성박 - 로드북)
해당 책이 출판되고 나서 많은 개발자들이 화를 냈음. 책 표지가 화장실에서 노트북을 하는 장면이었기 때문임. 미래도 없고 꿈도 없듯이 밤낮없이 화장실에서도 일하면서 과로로 쓰러지라는 것이냐! 라는 느낌이었기 때문. 기존 개발자들은 연봉도 오르지 않고 쇠퇴하는 경우가 많았기 때문에 프로그래머를 평가절하한 것이냐는 의견이었음. 프로그래머가 왜 되려고 하는 것인가? 대부분의 경우 프로그래밍이 어렸을 때부터 너무 재밌었기 때문에 프로그래머가 된다고 한다. 보통 모바일 게임의 경우 화장실에서도 볼일을 다보고도 계속 하듯이, 프로그래머가 되려고 한 자체는 결국에 이 일이 재밌고 즐거워서, 평생 할 수 있어서이기 때문이어야 할 것이다. 해당 책 소개를 의도한 이유는, 재밌다면 그 일을 계속 하라는 것을 이야기하고 싶어서이다. 코딩이 재밌다면 화장실이 아니라 어디에서 하든 상관없다. 하지만 나를 소진해가면서 밥벌이를 위해서라면 하지 마라는 것을 이야기하고 싶었다.
1.1 개발자??? or ?????
보통 신입사원 면접을 진행할 때 겪는 일이다. 기술면접 할 때 아이스브레이킹 시간을 가지고 간단한 기술문제를 푼 이후 난이도 조절을 통해 다음단계를 진행하게 된다. 아래는 3-5년차 자바 개발자를 대상으로 면접을 할 때 냈던 문제이다.
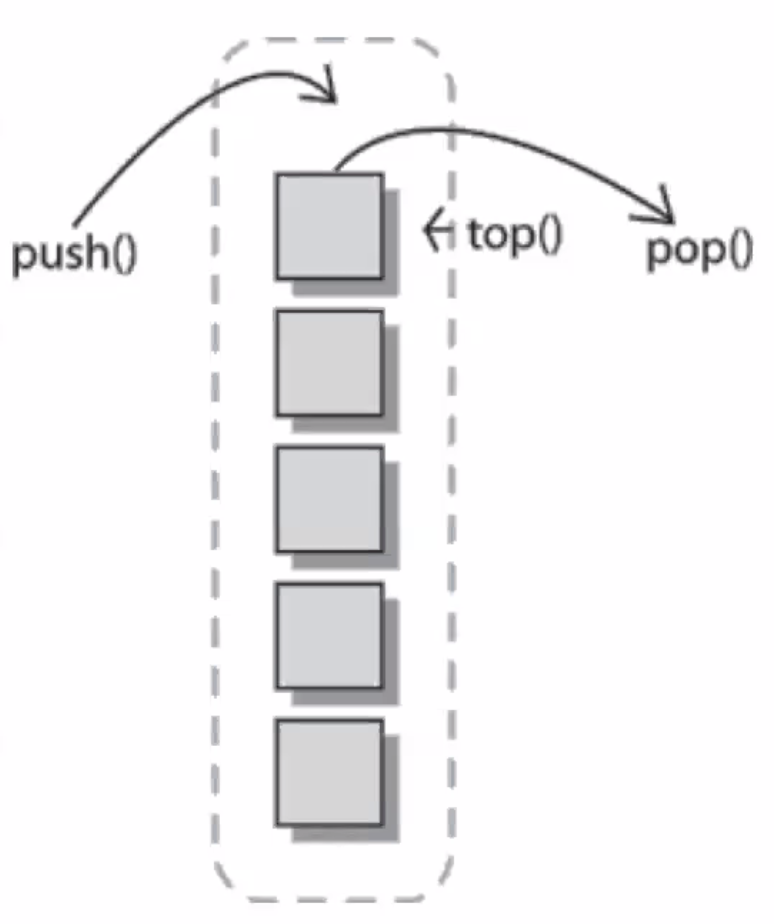
위의 문제를 가지고 해당 자료구조(스택)를 만들어보라는 문제를 냈다. 하지만 클래스 선언도 못하는 경우가 허다했다. 이력서는 화려한데 왜 못하지..? 라고 물어보면 “최근에는 개발보단 관리를 많이 하느라..” 라는 답변이 돌아온다. 이런 상황이 이해가 되지 않았음. ‘읭?’
1.2 개발(놈) Begins - 업무 할당
프로그래밍 관련 학과를 졸업하고, 현업에서의 시간도 어느정도 지났는데 왜 하지 못할까라는 고민에 대한 고찰.
회사에 처음 가서 어떤 과제를 받았다고 해보자. 정상적이지 않은 회사라고 한다면 대부분 “이 일을 언제까지 끝낼 수 있겠니? 참고로 시간이 없어.” 라면서 일을 시킨다. 무조건 그 시간안에 다 해야 하고, 심지어 충분한 레퍼런스나 리소스도 없다. 관리자가 시간만 관리하고 기술적 지원/교육도 없는 상태에 데드라인에 맞춰서 일을 끝내야 하는 상황에 놓였다고 상상해봐라..