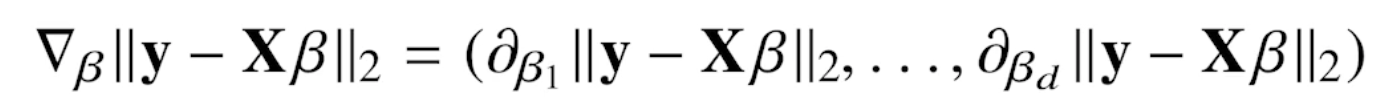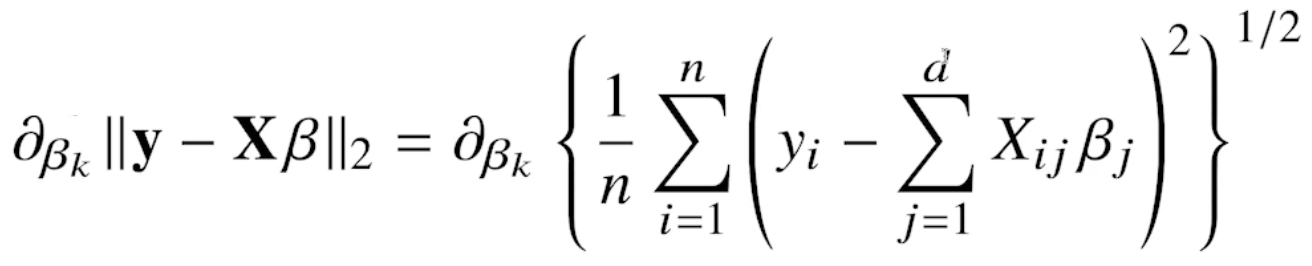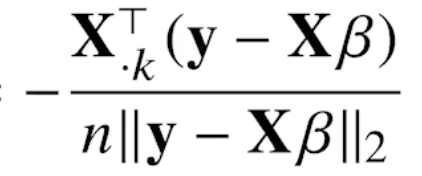# 본문은 위에 작성 ######## 본문은 한 줄에 최대 72 글자까지만 입력 ########################### -> |
# 꼬릿말은 아래에 작성: ex) #이슈 번호
# --- COMMIT END --- # <타입> 리스트 # feat : 기능 (새로운 기능) # fix : 버그 (버그 수정) # refactor: 리팩토링 # style : 스타일 (코드 형식, 세미콜론 추가: 비즈니스 로직에 변경 없음) # docs : 문서 (문서 추가, 수정, 삭제) # test : 테스트 (테스트 코드 추가, 수정, 삭제: 비즈니스 로직에 변경 없음) # chore : 기타 변경사항 (빌드 스크립트 수정 등) # ------------------ # 제목 첫 글자를 대문자로 # 제목은 명령문으로 # 제목 끝에 마침표(.) 금지 # 제목과 본문을 한 줄 띄워 분리하기 # 본문은 "어떻게" 보다 "무엇을", "왜"를 설명한다. # 본문에 여러줄의 메시지를 작성할 땐 "-"로 구분 # ------------------
git config --global commit.template ~/.gitmessage.txt 해당 gitmessage.txt를 전역 커밋 템플릿으로 설정한다.
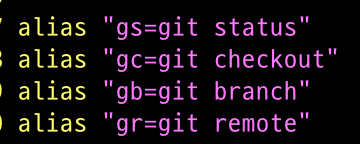
Alias 적용하기. 아래와 같이 alias 를 (맥이라면 ./zshrc) 저장하면 단축어로 사용할 수 있다.