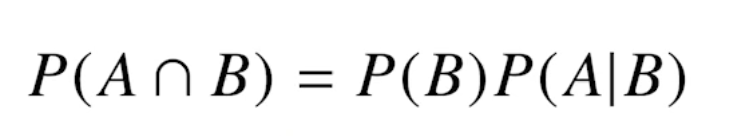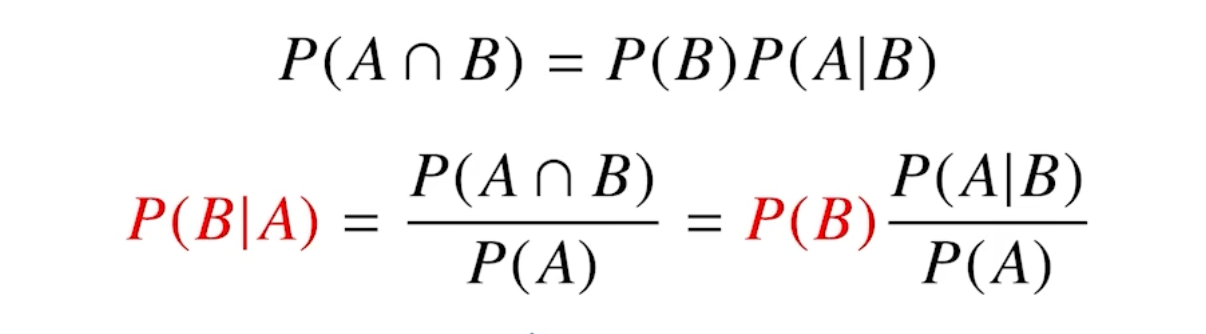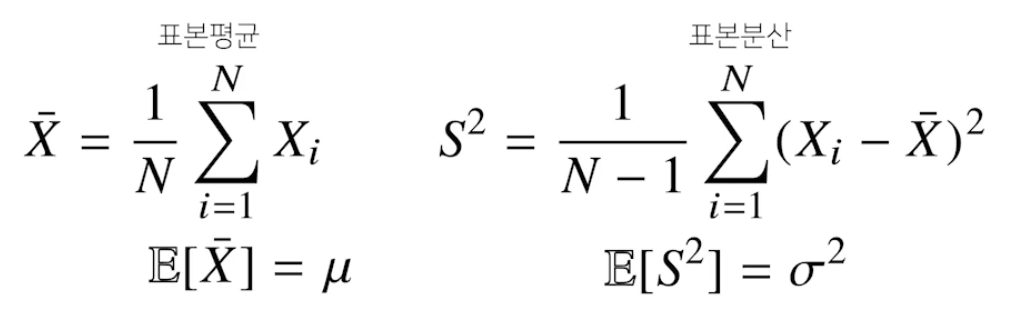CNN 첫걸음
- 지금까지 배운 다층신경망(MLP) 구조는 각 뉴런들이 선형모델과 활성함수로 모두 연결된 (fully connected) 구조였다.
- Convolution 연산은 이와 달리 커널(kernel)을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조이다.
- Convolution 연산의 수학적 의미는 신호(signal)을 커널을 이용해 국소적으로 증폭 또는 감소시켜서 정보를 추출 또는 필터링하는 것이다.
- 커널은 정의역 내에서 움직여도 변하지 않고(translation invariant) 주어진 신호에 국소적(local)으로 적용한다.
2차원 Convolution 연산
커널을 입력벡터 상에서 움직여가면서 선형모델과 합성함수가 적용되는 구조
입력크기를 (H, W), 커널 크기를 $(K_H, K_W)$, 출력 크기를 $(O_H, O_W)$ 라고 하면 출력 크기는 다음과 같이 계산한다.
채널이 여러개인 2차원 입력의 경우 2차원 Convolution을 채널 개수만큼 적용한다. 텐서를 직육면체 블록으로 이해하면 좀 더 이해하기 쉬움.
Convolution 연산은 커널이 모든 입력데이터에 공통으로 적용되기 때문에 역전파를 계산할 때도 convolution 연산이 나오게 된다.