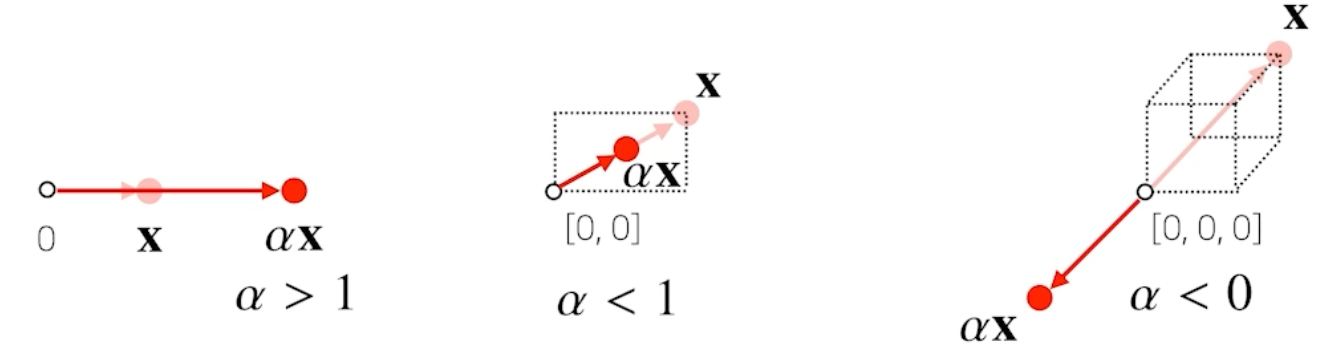
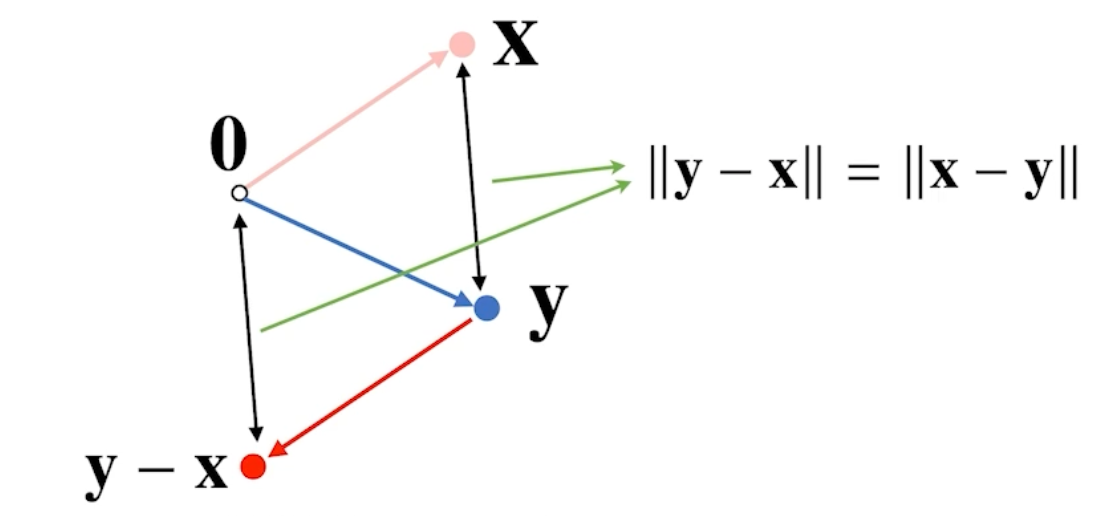
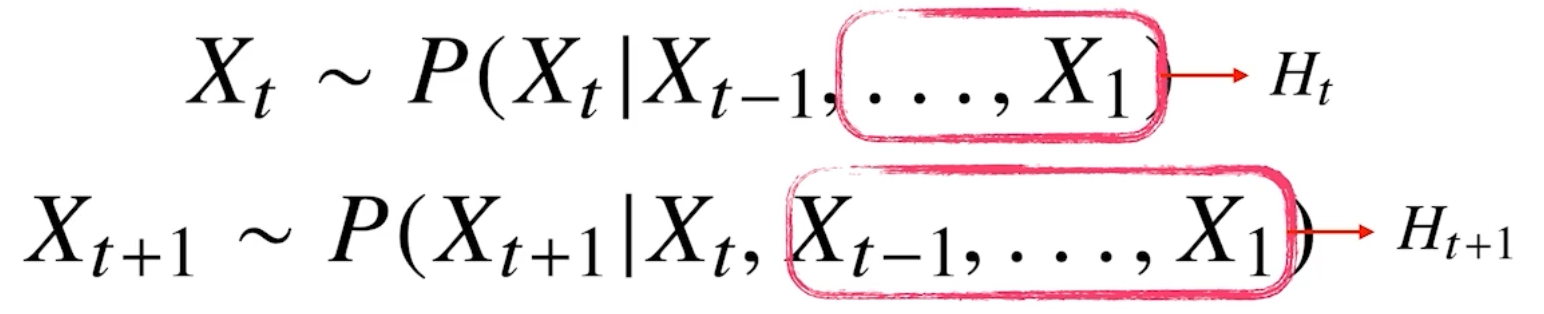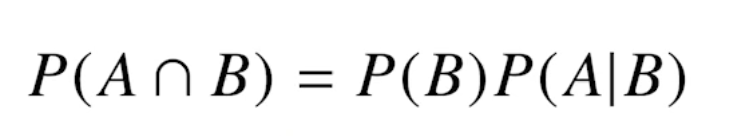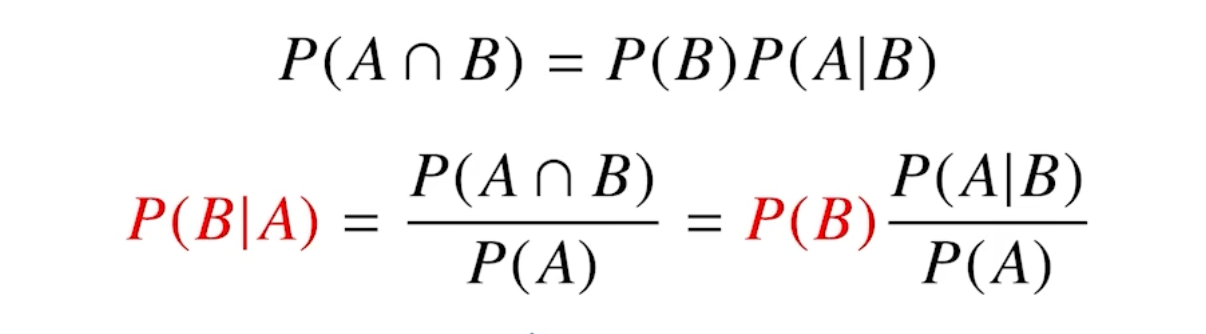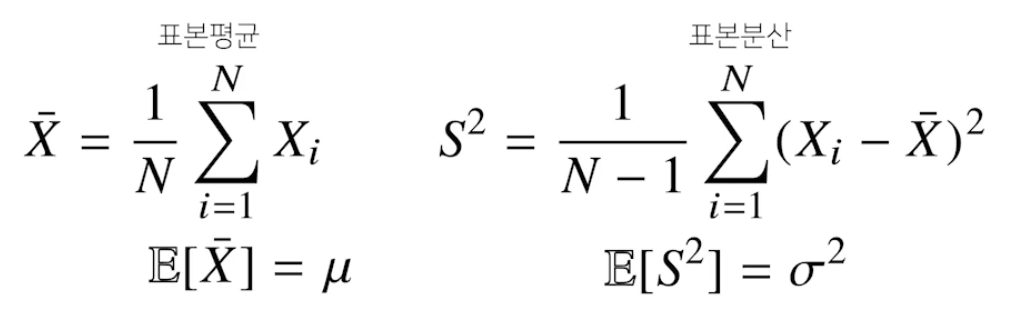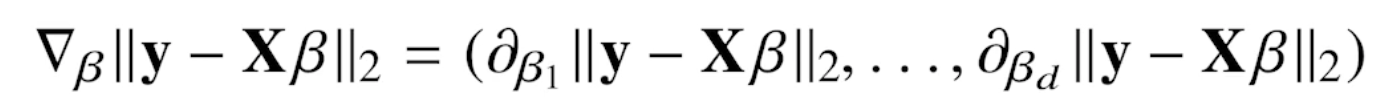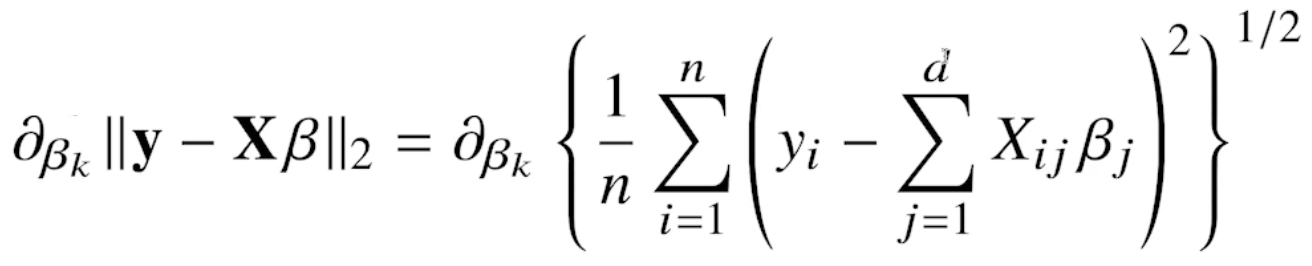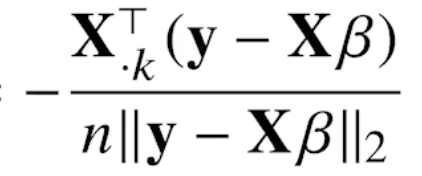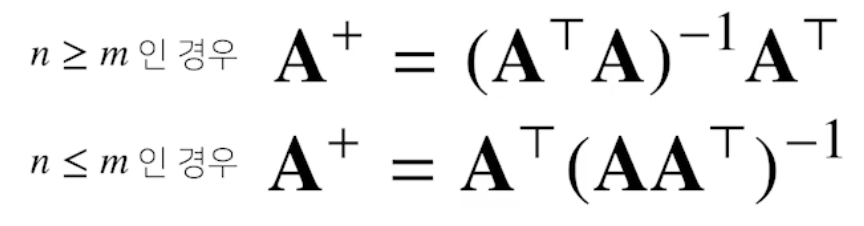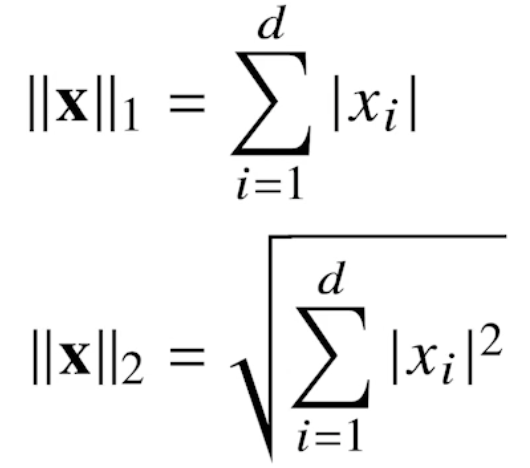그리스문자 정리
| 문자 | 영어 | 한글 | 로마자 표기법 |
| Α α | Alpha | 알파 | a |
| Β β | Beta | 베타 | b |
| Γ γ | Gamma | 감마 | gh, g, j |
| Δ δ | Delta | 델타 | d, dh |
| Ε ε | Epsilon | 엡실론 | e |
| Ζ ζ | Zeta | 제타 | z |
| Η η | Eta | 에타 | i |
| Θ θ | Theta | 쎄타 | th |
| Ι ι | Iota | 요타 | i |
| Κ κ | Kappa | 카파 | k |
| Λ λ | Lambda | 람다 | l |
| Μ μ | Mu | 뮤 | m |
| Ν ν | Nu | 뉴 | n |
| Ξ ξ | Xi | 크시 | x, ks |
| Ο ο | Omicron | 오미크론 | o |
| Π π | Pi | 파이 | p |
| Ρ ρ | Rho | 로 | r |
| Σ σ ς | Sigma | 시그마 | s |
| Τ τ | Tau | 타우 | t |
| Υ υ | Upsilon | 입실론 | y, v, f |
| Φ φ | Phi | 피 | f |
| Χ χ | Chi | 카이 | ch, kh |
| Ψ ψ | Psi | 프사이 | ps |
| Ω ω | Omega | 오메가 | o |