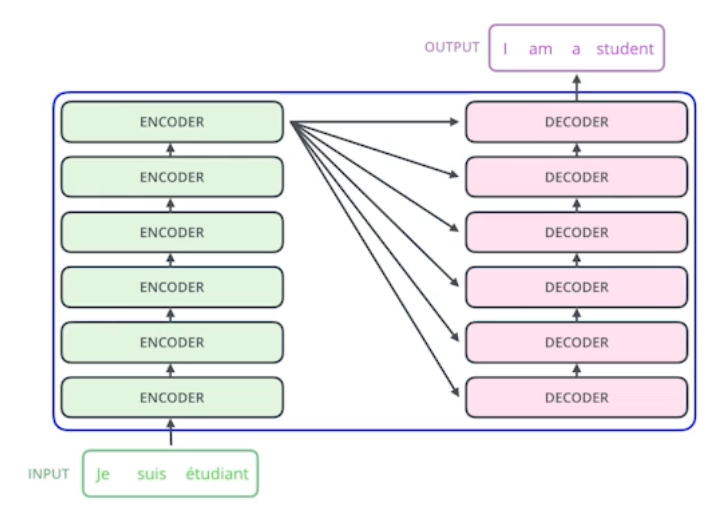
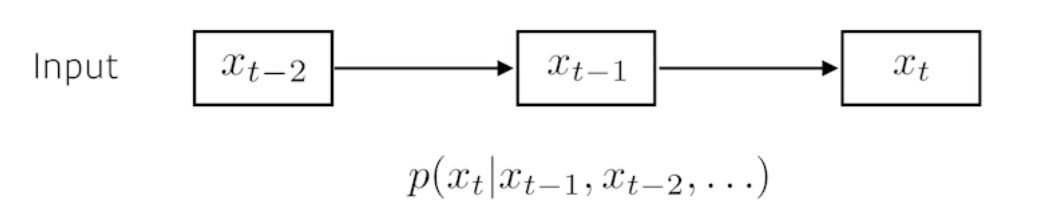
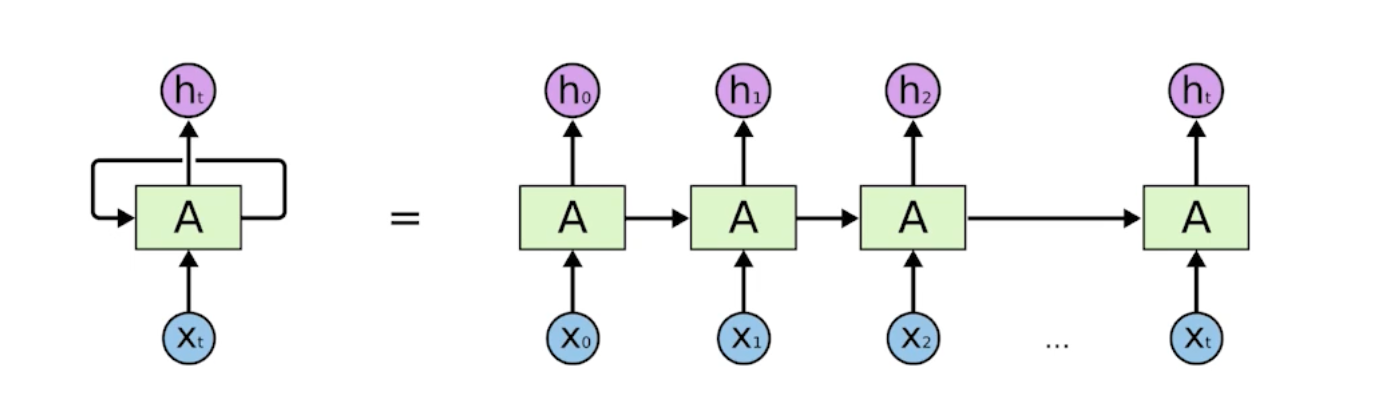
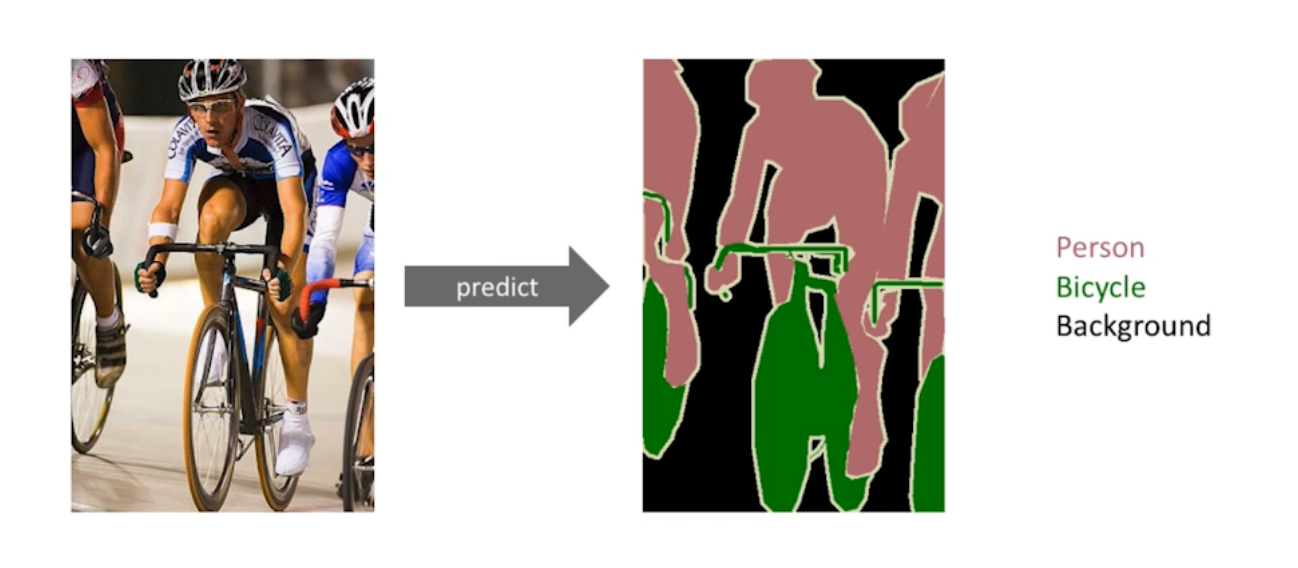
Generative Models 소개
What I cannot create, I do not understand. - Richard Feynman
생성 모델을 학습한다는 것에 대해서 가장 처음에 생각하는 것은 그럴듯한 문장 혹은 이미지를 만드는 것이라고 생각한다. 하지만 이것이 전부가 아니라, 생성모델은 그것보다 많은 것을 포함하는 개념이다.
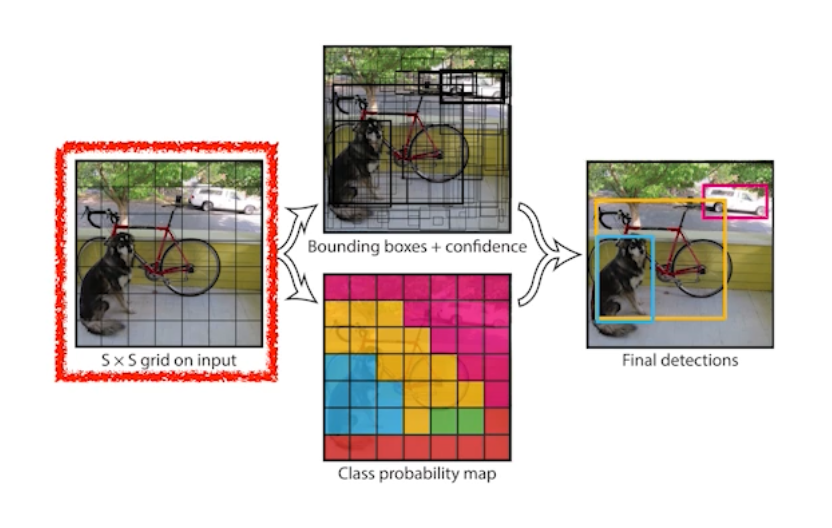
Generation: 강아지와 같은 이미지를 만드는 것도 생성모델이 하는 일이지만, Density estimation 어떤 이미지가 들어왔을 때 확률값 하나가 튀어나와서 이미지가 고양이 같은지 강아지 같은지 강아지가 아닌 것 같은지 구분하고 싶은 것임. 이상행동감지로 활용될 수 있다. 엄밀히 생성모델은 Discrimity 모델을 포함하고 있다. 즉 생성해내는 것만 아니라 구분하는 것까지 포함하고 있다.
이러한 모델을 보통 explicit model 이라고 한다. 확률값을 얻을 수 있는 모델을 뜻함.
Unsupervised representation learning 이라고 강아지가 있으면 강아지는 귀가 두개고 꼬리가 있고 등의 특성이 있을텐데 이것을 feature learning 이라고 한다. 이 feature learning이 생성모델이 할 수 있는 것으로 표현하기도 함.
Basic Discrete Distributions
- Bernoulli distribution
- 이것을 포함하는 확률분포에는 숫자가 하나 필요함. 동전을 던졌을 때 앞 뒤가 나오는 것. 카테고리면 n개가 필요한 것. 주사위를 던졌을 때 n개가 필요한 것이 아니라 n - 1개가 필요함.
- Categorical distribution
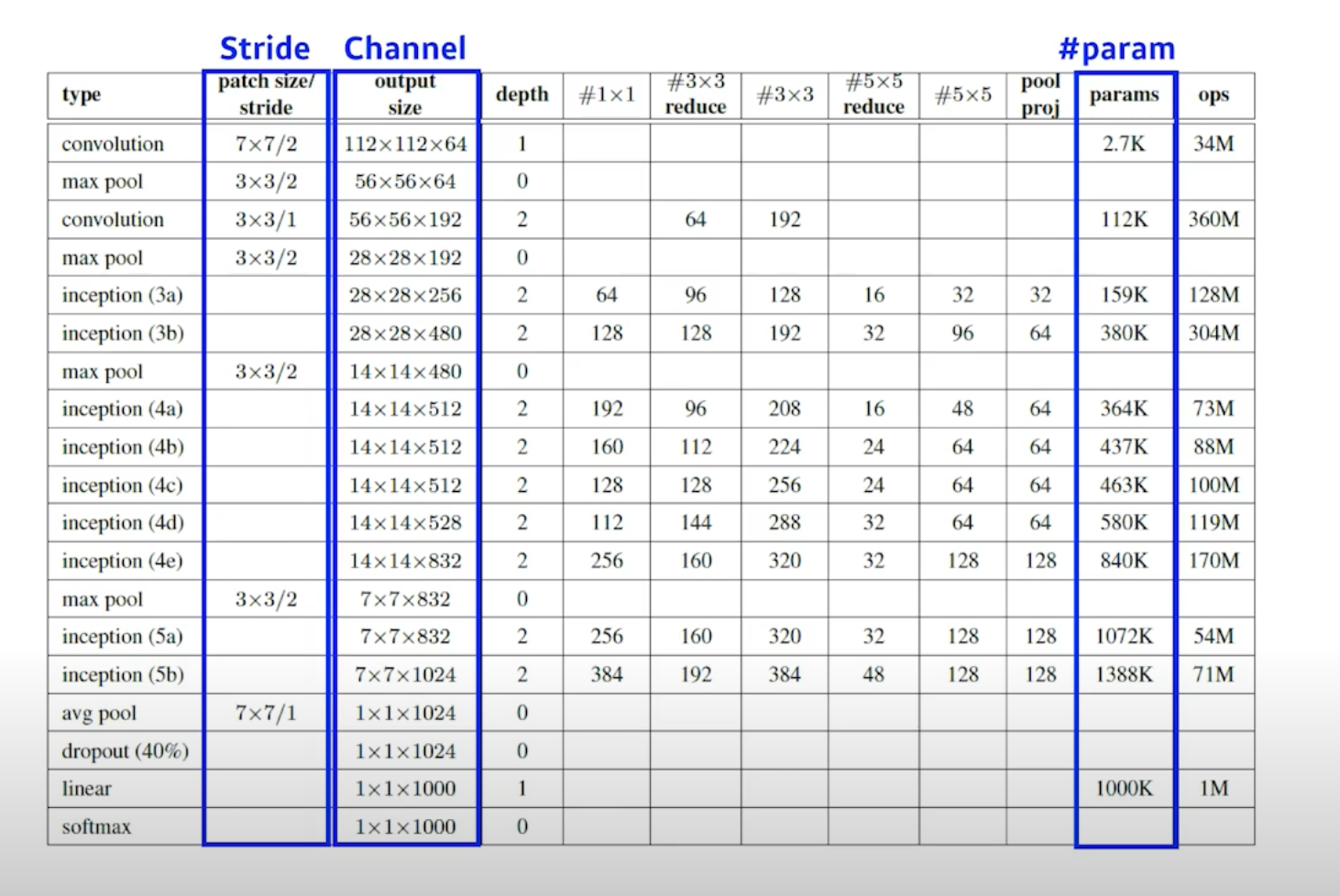
RGB 이미지 하나를 픽셀로 표현할 때 (r, g, b) ~ p(R, G, B) 는 256 256 256 가지가 있다. 그렇다면 이것을 표현하는 파라미터는 256 256 (256 - 1) 개가 필요함.