PStage MRC 7강 - Linking MRC and Retrieval
Introduction to Open-domain Question Answering (ODQA)
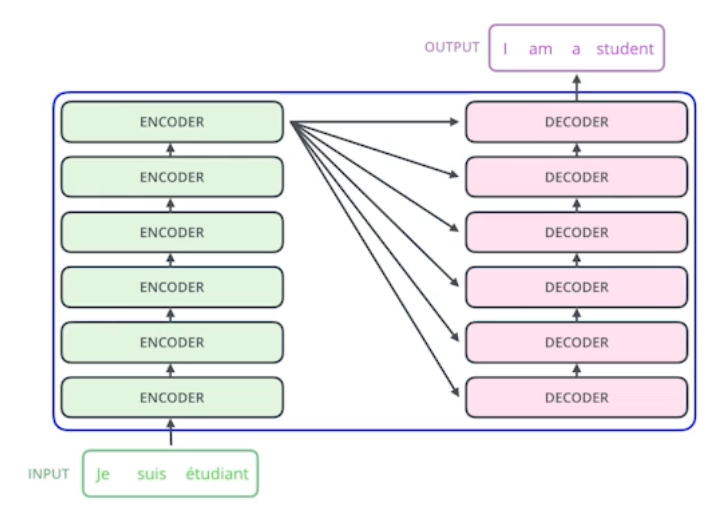
MRC는 지문이 주어진 상황에서 질의응답을 하는 과제이다. 이에 반해 ODQA는 비슷한 형태이지만, 지문 부분이 주어지는 것이 아니라 위키 혹은 웹 전체가 주어지게 되기 때문에 매우 많은 지문을 봐야하는 Large Scale 과제가 된다.
ODQA라는 문제는 꽤 예전부터 다루었던 문제이며, short answer with support의 형태를 목표로 했었다.
1) Question processing
질문으로부터 키워드를 선택하여 답변의 타입을 선택할 수 있도록 했다.
2) Passage Retrieval
기존 IR 방법을 활용하여 연관된 document를 뽑고, passage 단위로 자른 후 선별한다.
3) Answer processing
주어진 질문과 passage들 내에서 답을 선택하는 휴리스틱한 분류문제로 진행했다.
ODQA는 꽤 역사가 길며, 지금까지는 위와 같은 방식으로 진행되고 있었는데, 2011년 IBM Watson을 통해 발전하게 된다.