부스트캠프 AI Tech 9주차 회고 (2021-09-27 ~ 2021-10-01)
P Stage 강의 커리큘럼
- 인공지능과 자연어 처리
- 자연어의 전처리
- BERT 언어모델 소개
- 한국어 BERT 언어 모델 학습
- BERT 기반 단일 문장 분류 모델 학습
- BERT 기반 두 문장 관계 분류 모델 학습
- BERT 언어모델 기반의 문장 토큰 분류
대회관련
협업전략, 툴
협업툴
협업툴은 Notion을 메인으로 사용한다. 여러 툴에서 파편적인 기능들만을 선별적으로 사용할 수도 있지만, 데드라인이 주어진 대회라는 플랫폼 하에서는 채널이 다양할 수록 혼란만 가중되는 것 같다. Notion에서 여러 유용한 Template을 하나하나 가져와서 꽤 괜찮은 Dashboard를 만들고, 코드관리를 제외한 모든 것을 Notion으로 해결하고 있다. 기록의 중요성에 공감을 많이 하여 모인 팀 답게, Notion을 적극적으로 사용하고 있고 그로인해 체계적인 실험과 작업관리가 가능해진 것 같다.
또한 Wandb를 팀단위로 만들어서 각자 한 실험에 대한 log를 시각화하여 볼 수 있게 되었다. good practice인듯!!
협업전략
실험전략은 개인이 하고싶은 것 위주로 플래닝을 진행하며, 작은 모델을 Base로 하여 빠른 실험이 가능하도록 했다. 또한 실험을 통한 성능비교를 위해 hyperparameter나 seed등 변수가 될 수 있는 모든 것들을 fix하여 진행한다. 코드의 경우 본인의 실험에 따라 각자의 코드가 전부 달라지며, 그것을 하나로 통합하면서 진행하는 것은 대회에서는 굉장히 비효율적인 방식인 것 같다. 한 번 진행해보고 PR이나 Merge에 병목이 생기는 것을 경험한 뒤로, 언제든 그때그때의 실험으로 Rollback이 가능하도록 branch를 여러개로 나누되, 합치진 않기로 결정했다.
NLP Augmentation
NLP에서 Text Augmentation 방법은 크게 텍스트의 일부를 변형하여 데이터를 증강하는 방법과 생성모델을 사용하여 새로운 텍스트를 생성하여 데이터를 증강하는 방법이 있다. 그 중에서 가장 손쉽게 접근할 수 있는 방법은 KoEDA 라이브러리를 사용하는 것이었다.
KoEDA는 EDA와 AEDA 논문에서 소개된 방식을 한국어 Wordnet 으로 Porting하여 공개한 오픈소스 라이브러리이다.
EDA의 경우 SR, RI, RS, RD 네 가지 Operation을 제공하며, 한 문장에 대해서 몇 개의 문장을 만들건지에 따라 $\alpha$ 값에 조정이 필요하며, 4문장 이하는 $p=0.1$, 4문장 초과는 $p=0.05$ 정도의 확률값으로 데이터를 변형하는게 가장 성능이 좋았다고 저술되어있다. 하지만 텍스트 데이터의 특성상, 위치를 바꾸거나 일부 단어를 제거하는 것은 결국 본 문장의 의미를 손실시키는 행위이기 때문에AEDA방법론이 등장하게 된다.AEDA는 문장을 손실시키지 않게 하기 위해 Special character를 문장 곳곳에 배치하는 방법론으로, 역시 많은 특수문자가 들어가게 되면 성능이 떨어지기 때문에 적절한 확률값을 찾는 것이 중요하다.
KoEDA의 Snippet1
2
3
4
5
6
7
8
9
10
11
12
13augmenter = EDA(
morpheme_analyzer: str = None, # Default = "Okt"
alpha_sr: float = 0.1,
alpha_ri: float = 0.1,
alpha_rs: float = 0.1,
prob_rd: float = 0.1
)
result = augmenter(
data: Union[List[str], str],
p: List[float] = None, # Default = (0.1, 0.1, 0.1, 0.1)
repetition: int = 1
)
1 | augmenter = AEDA( |
- 하지만
EDA,AEDA모두 KLUE-RE Task에선 별 효과가 없는 것 같다..
다음 방법은 생성모델을 활용한 방법으로 Conditional BERT Contextual Augmentation 논문에 소개되었다. 기존 BERT에서는 token embedding + segment embedding + positional embedding 으로 representation을 구성하지만, conditional BERT의 경우 token embedding + label embedding + positional embedding 으로 representation을 구성하고, label을 부착한 상태로 데이터셋을 MLM task로 pretraining한다. 이후에 mask token을 replace하는 것과 마찬가지로 label에 대하여 token replace를 수행한다.
- 논문을 자세히 읽어보진 않았지만, 충분히 시도해볼만한 가치가 있는 것 같긴 하다. 현재 augmentation에 대한 효과를 전혀 보지 못했기 때문에 이번 실험이 끝나면 해봐야지…
Huggingface
살면서 huggingface 공식문서를 가장 많이 읽은 한 주였다. Trainer와 Tokenizer는 거의 다 읽어는 봤는데, 기능이 너무 많아서 두고두고 찾아보면서 개발해야할 것 같다.
그 중에서 인상깊은 기능들은 아래와 같다.
hyperpameter_search of Trainer class (Huggingface, transformers)
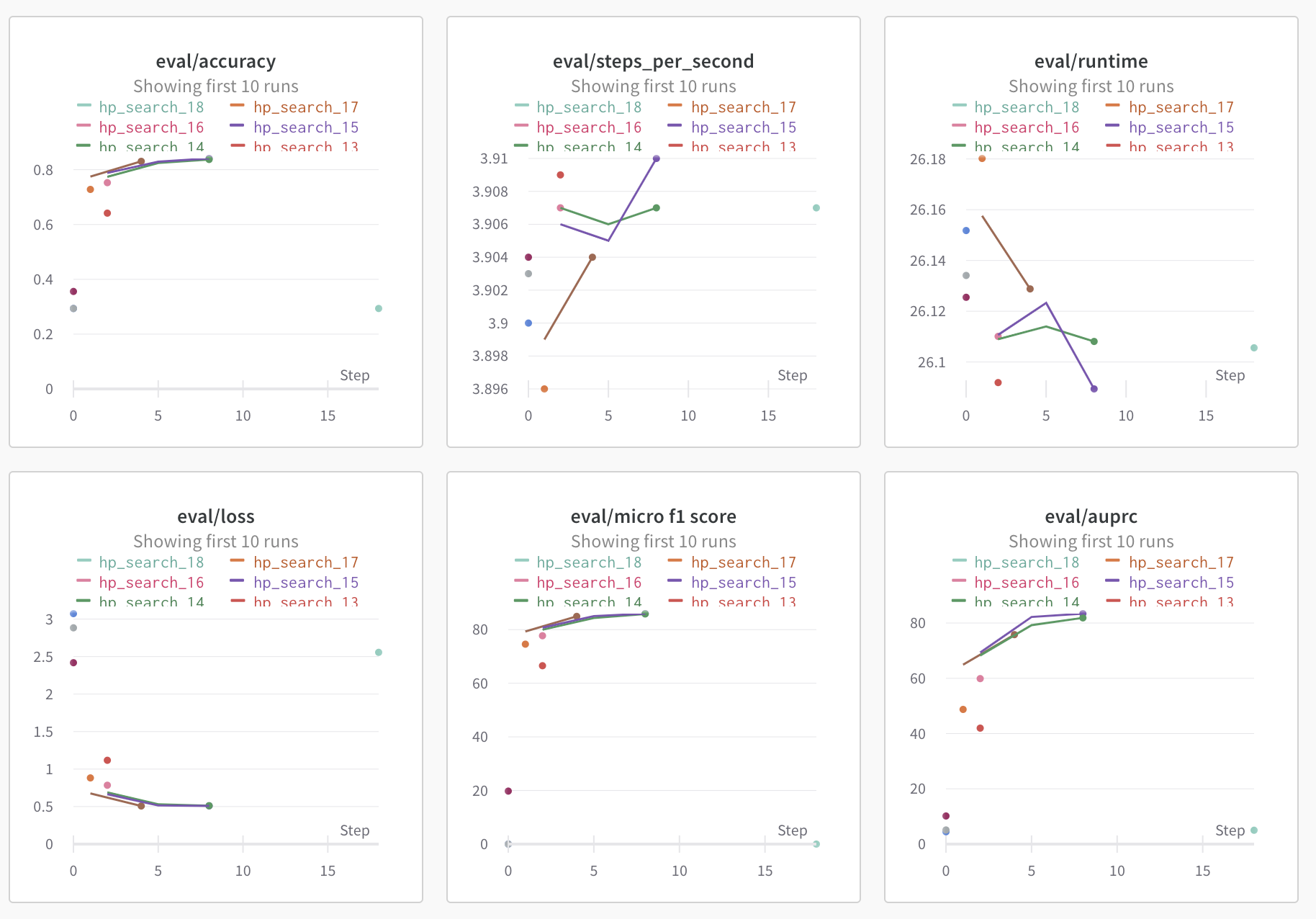
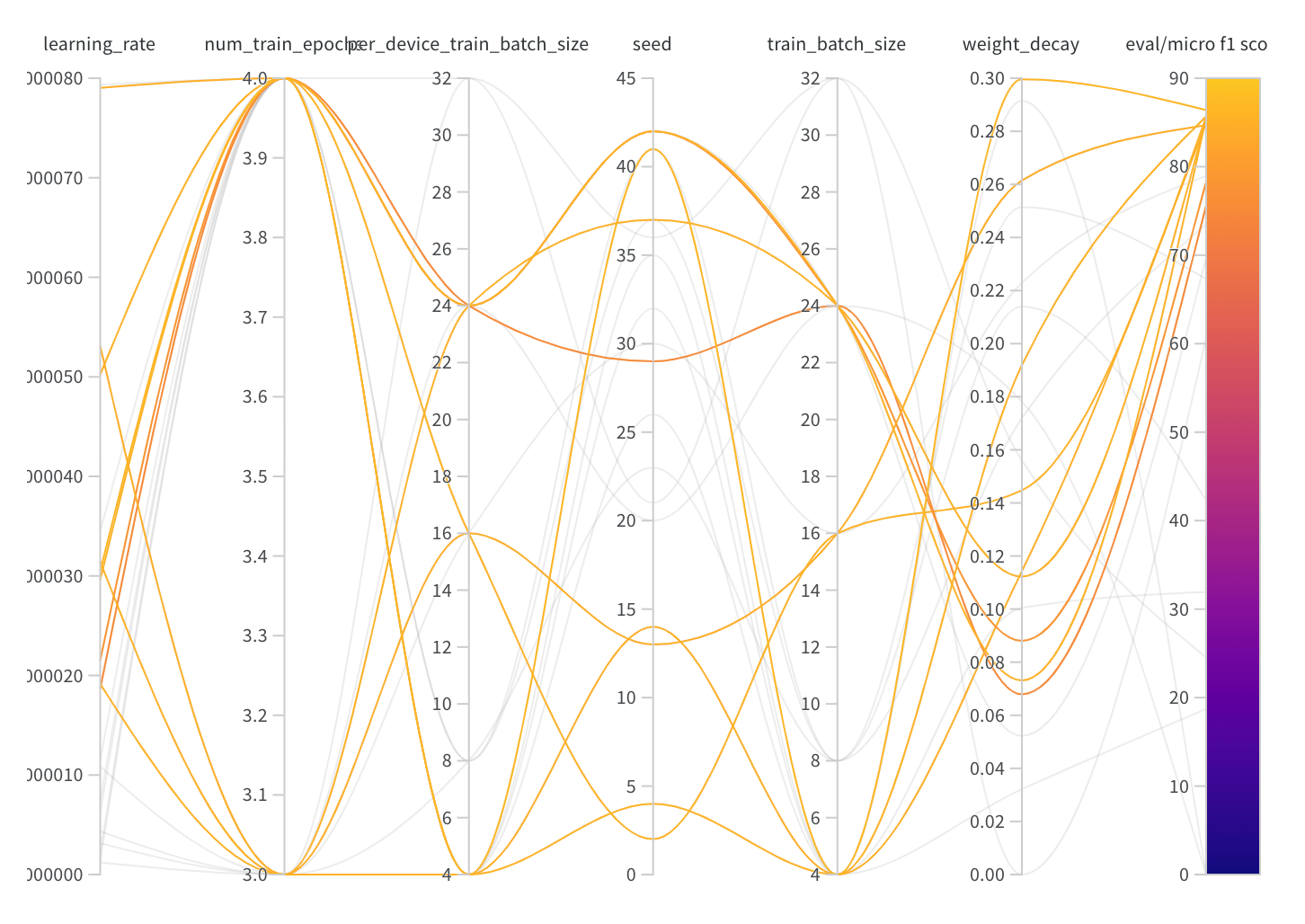
KLUE RE(Relation Extraction) 과제를 하면서 모델을 finetuning 해보다가 hyperparameter가 생각보다 성능에 많은 영향을 준다는 것을 알게 되었다. 그에 따라 huggingface transformers의 Trainer 클래스에서 제공하는 hyperparameter_search 를 사용하여 최적의 hyperparameter를 찾아보는 실험을 하게 되면서 사용법을 알 필요가 있었다.

trainer의 hyperparameter_search method를 보시면, 하이퍼파라미터를 찾을 때 optuna , Ray Tune, SigOpt 세 친구들을 통해 hyperparameter를 탐색할 수 있다. huggingface의 trainer가 train 시 wandb와 연동되는 메커니즘과 비슷하다고 이해하면 될듯.
Snippet
1 | from transformers import AutoModelForSequenceClassification, AutoConfig, AutoTokenizer, Trainer, TrainingArguments |
사용법은 생각보다 간단하다. hp_space 함수에서 원하는 하이퍼파라미터와 그 하이퍼파라미터의 범위를 key, value 형태로 return 해주면 해당 dictionary를 토대로 실험이 진행된다. 위에서는 3개의 하이퍼파라미터만 작성되어 있지만 warmup_steps, weight_decay, per_device_train_batch_size 등을 동일한 방식으로 추가할 수 있고, training argument에 들어가는 대부분의 hyperparameter들을 탐색할 수 있는 것 같다.
하지만 위에서 사용하는 optuna 혹은 raytune이 hyperparameter를 탐색하는 알고리즘도 다르고, CLIReporter, Pruner, Scheduler 또한 전부 다르기 때문에 해당 라이브러리에 대한 이해가 필요한 것 같다.
backend (
strorHPSearchBackend, optional) – The backend to use for hyperparameter search. Will default to optuna or Ray Tune or SigOpt, depending on which one is installed. If all are installed, will default to optuna.
- default 는 optuna 로 설정되어 있고, 자신의 환경에 설치되어 있는 걸 우선적으로 사용하도록 되어있다.
하이퍼파라미터를 search하는 direction을 maximize 또는 minimize로 설정할 수 있는데, 이 때 사용자의 입맛대로 목적함수를 작성하여 사용할 수도 있다.
1 | def my_objective(metrics): |
custom object function의 경우 공식문서나 discussion 참고할 것.
- Ray https://docs.ray.io/en/latest/tune/index.html
- optuna https://optuna.org/#code_examples
- https://discuss.huggingface.co/t/using-hyperparameter-search-in-trainer/785/10
Focal Loss
다음은 Focal Loss function인데, 이번 대회에서 효과를 톡톡히 보았다. Focal Loss란 RetinaNet 논문에서 처음 제안되었는데, Class Imabalance를 해결하기 위한 목적함수이다. 쉽게 말하면 예측하기 쉬운 값에 대해서는 0에 가까운 loss값을 부여하고, 예측하기 어려운 negative sample에 대해서는 기존보다 높은 loss값을 부여하여 weighted scale의 형태로 표현할 수 있게 만든 손실함수이다.
이것 역시 나중에 꼭 본 논문을 읽어보도록 하자….
Reference
- [딥러닝 기계 번역] Seq2Seq: Sequence to Sequence Learning with Neural Networks (꼼꼼한 딥러닝 논문 리뷰와 코드 실습)
- Paper Reivew - FastText: Enriching Word Vectors with Subword Information
- 한국어 자연어처리 1편_서브워드 구축(Subword Tokenizer, Mecab, huggingface VS SentencePiece)
- huggingface transformers의 attention mask
- huggingface tokenizer로 konlpy 사용하기
- BERT 톺아보기
- LM Training from scratch
- 나만의 BERT Wordpiece Vocab 만들기
- 나만의 언어모델 만들기 - Wordpiece Tokenizer 만들기
- BERT만 잘 써먹어도 최고가 될 수 있다
부스트캠프 AI Tech 9주차 회고 (2021-09-27 ~ 2021-10-01)
