WaveNet 리뷰
Short Summary
적은 데이터셋과 단일 모델만으로 다양한 오디오 파형을 생성할 수 있어서 TTS, 음악, Voice Conversion 등 분야에서 SOTA(state-of-the-art)를 기록한 WaveNet은 화자의 Identity나 음악의 장르 등을 특징($h$)으로 추가하면 특징에 맞는 output을 산출할 수 있는 확률적 모델이자 자기회귀(AR) 모델이다.

이전에 신호처리와 Image Segmentation에 사용되던 Causal Convolution은 많은 레이어를 필요로했고, Receptive Field를 확장시키기 위해서는 큰 필터가 필요하여 연산에 많은 비용이 들었다. WaveNet은 이러한 문제들을 Dilated Convolution을 사용하여 Receptive Fields를 효율적으로 넓힐 수 있었다. 그 결과 Causal Convolution보다 연산비용을 줄이고 학습속도를 시퀀셜 모델을 처리하던 RNN, LSTM보다 획기적으로 줄일 수 있었다.
기존 16bit 정수형 시퀀스로 저장되던 음성신호들의 연산에는 각 레이어마다 65,536개의 확률 계산이 필요했는데, $\mu$-law companding transformation 방법을 사용하여 256개의 신호로 양자화시킬 수 있었다. Activation Unit Gate (LSTM에서의 input게이트와 유사) 를 사용하여 linguistic features (주파수, 음의 높낮이, 숨소리, 세기 등)들을 재현할 수 있었다.
Abstract
- WaveNet은 음성의 파형을 생성하는 모델.
- 과거의 음성 데이터 $x_1, x_2, … , x_{t - 1}$ 가 주어졌을 때 $t$ 시점을 기준으로 $x_t$ 라는 데이터가 음성으로써 성립할 확률 $P(x_1, …, x_{T-1}, x_T)$ 을 학습한 확률론적(probabilistic) 모델이자 자귀회귀(autoregressive) 모델이다.
- TTS(Test-To-Speech)에 적용할 때는 SOTA(당시 2016년)를 달성했고 영어와 중국어에서 사람의 음성만큼 자연스러웠음.
- WaveNet은 다양한 화자의 음성적 특징들을 동일한 정확도로 감지할 수 있음.
- 음악을 학습했을 때도 사실적인 음악 파형들을 생성했음.
Waveform을 결합확률분포로 표현 -> Conv Layer를 쌓아서 모델링하겠다.
Introduction
WaveNet은 PixelCNN 구조를 기반으로 한 Audio 생성모델이다.
WaveNet의 특징
- WaveNet은 이전에는 TTS 분야에서 불가능했던 자연스러운 음성 신호를 생성할 수 있다.
- long-range temporal dependencies를 해결하기 위해
dilated causal convolution을 개발했으며, receptive fields를 매우 크게 넓힐 수 있었다. - 단일 모델로 다양한 음성을 생성할 수 있다.
- 적은 음성인식 데이터셋으로도 좋은 성능을 낼 수 있으며 TTS, 음악, Voice Conversion 등 여러 분야에 응용될 수 있다.
WaveNet
WaveNet은 Audio의 파형을 직접적으로 생성할 수 있다.
파형 $x = \{x_1, \ …,\ x_T\}$ 의 결합확률은 아래와 같이 조건부확률의 곱으로 표현될 수 있다.
즉, 각각의 오디오데이터 $x_t$ 는 모든 이전 timestep을 바탕으로 조건부 확률이 계산되고, 그 확률을 이용하여 다음 시점의 오디오를 생성할 수 있다.
PixelCNN과 유사하게 조건부확률분포는 Convolution Layer의 스택으로 모델링된다. 여기에는 Pooling Layer가 없고 모델의 output은 input의 차원과 동일하다. 모델은 현재 시점의 데이터 $x_t$ 에 대해서 softmax와 최적화를 거쳐 다항분포를 산출한다.
Dilated Causal Convolutions
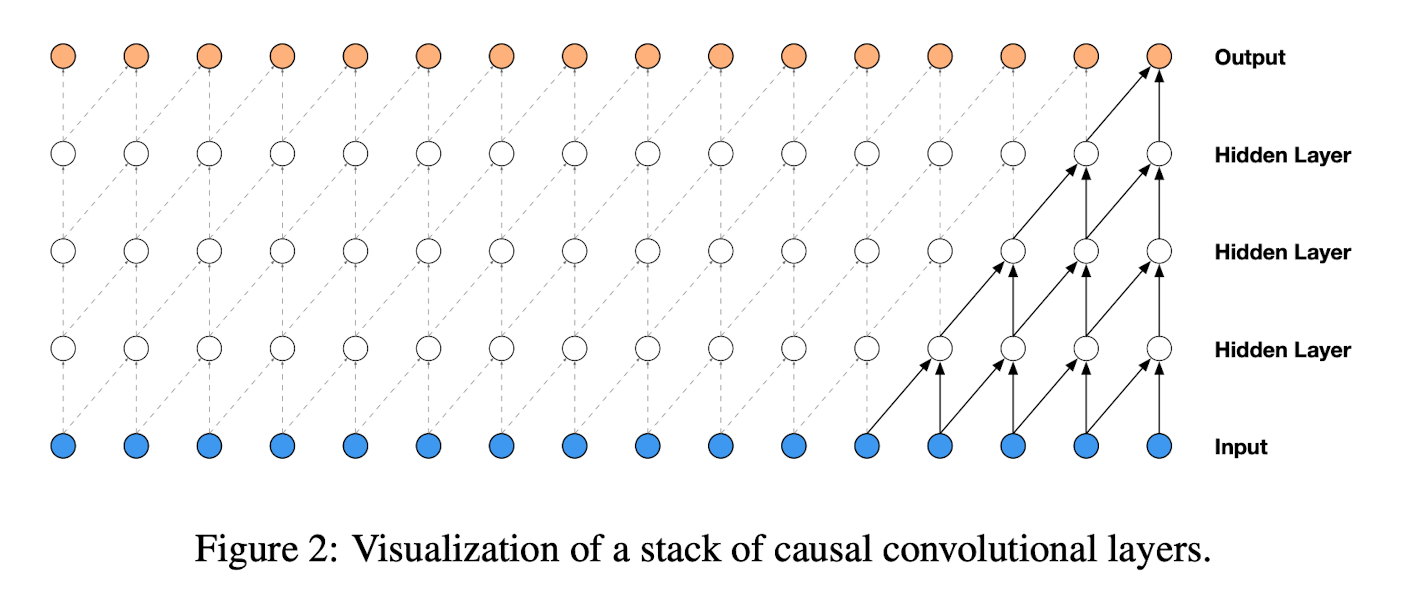
WaveNet의 핵심은 Causal Convolutions이다. 이것을 사용함으로써 데이터의 순서를 훼손하지 않을 수 있으며 그와 동시에 $P(x_{t+1}\ | \ x_1,\ …, \ x_t)$ 는 미래의 timestep인 $x_{t+1},\ x_{t+2},\ …,\ x_T$ 에 의존하지 않는다.
Causal Convolution의 핵심은 마스크텐서를 구성하고 convolution kernel에 적용하기 전에 mask와 elementwise 곱 연산을 수행하게 된다.
실측된 x를 알고있기 때문에 학습 시점에서 모든 타임스텝의 조건부확률은 병렬적으로 계산된다. 모델은 음성을 sequential한 확률로 만드는데, 각각의 예측값들이 산출된 이후에는 다음 예측으로 샘플들이 되돌아간다. Causal Convolutions 모델은 반복되는 connection들을 가지고 있지 않기 때문에 매우 긴 시퀀스를 적용하더라도 RNN보다 학습이 빠르다. Causal Convolution의 문제점 중 하나는 많은 레이어를 필요로하며, receptive field 를 확장시키기 위해 큰 필터가 필요하다는 것이다. 해당 논문에서는 엄청난 연산비용의 증가 없이 대규모의 receptive fields를 위해 dilated convolutions을 사용했다.
dilated convolution (옆으로 팽창한 합성곱)은 특정 스텝에서의 input을 스킵함으로써 그 길이보다 큰 영역에 필터를 적용시킨 합성곱이다. 이것은 Convolution에서의 pooling이나 strides와 비슷하지만 input과 output의 차원을 동일하게 하고 훨씬 효율적이다.
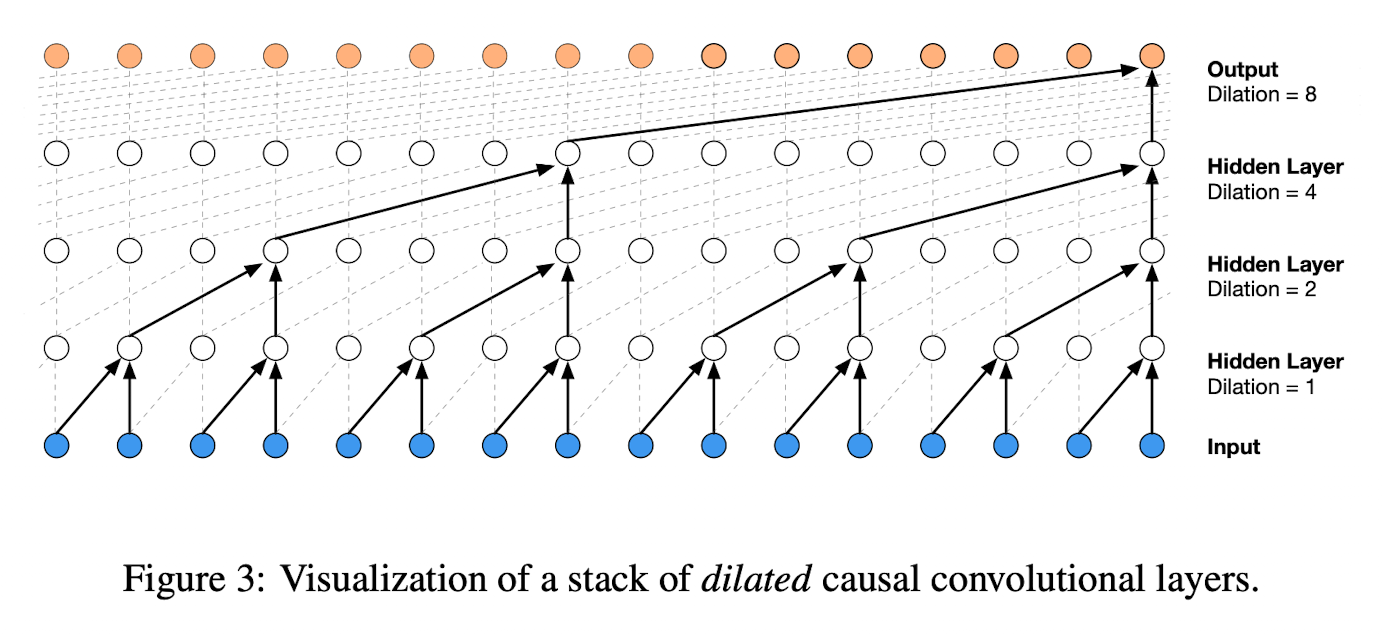
Dilated Convolution은 이전에 신호처리나 Image Segmentation에 사용되었다.
해당 논문에서는 $1, 2, 4, \ …, \ 512, 1, 2, 4,\ …, \ 512, 1, 2, 4, \ …, \ 512$ 총 30개의 dilations를 사용하였다.
Softmax Distributions
조건부 확률 분포를 모델링할 때의 접근방법 중 하나는 Mixture Density Network 혹은 MCGSM(mixture of conditional Gaussian scale mixtures) 혼합모델이었다. 그러나 PixelCNN 등장 이후 단순 연속된 데이터(이미지 픽셀이나 오디오 샘플 등)에도 Softmax 분포가 대체로 성능이 더 좋다고 알려졌다. 이 이유 중 하나는 shape에 대한 가정이 없기 때문에 다항분포가 더 유연하고 쉽게 임의의 확률분포를 모델링할 수 있다는 것이다.
원시 오디오샘플은 전형적으로 16비트 정수형 시퀀스로 저장되기 때문에, softmax layer는 매 타임스텝마다 65,536개의 확률을 다뤄야 할 필요가 있다. 이것을 더 다루기 쉽게 하기 위해 $\mu$-law companding transformation(ITU-T) 방법을 적용했고, 256개로 양자화시킬 수 있었다.
이러한 비선형적 양자화는 선형적인 스키마보다 상당히 의미있는 재현을 해냈다. 특히 Speech 분야에서 더욱 original과 가까운 신호를 재현해냈다.
Gated Activation Units
WaveNet에는 PixelCNN에서 사용된 Activation Unit Gate가 똑같이 사용된다.
- $*$: convolution operator
- $\odot$: element-wise multiplication
- $\sigma$: sigmoid
- $k$: layer index
- $f\ and\ g$: filter and gate.
- $W$: learnable convolution filter.
Residual And Skip Connections
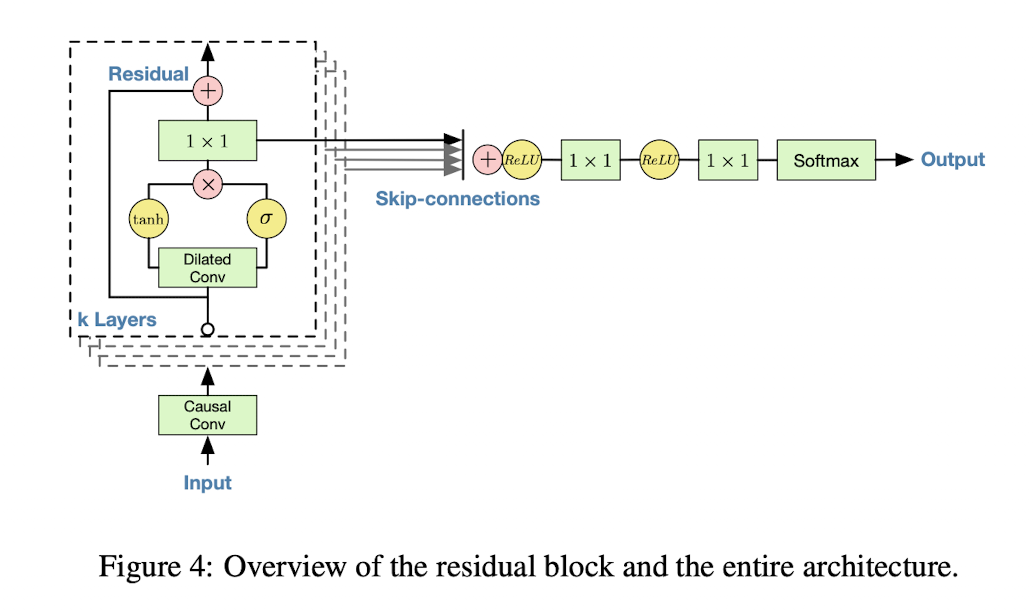
Residual 과 Skip Connections가 네트워크에 사용되었는데, 이 덕분에 수렴하는 속도가 빨라지고 더욱 깊은 신경망도 학습이 가능해졌다. Residual과 Skip-Connections 들이 신경망마다 Stacking 되어 있다.
Conditional WaveNets
WaveNet은 Conditional Modeling $P(x|h)$ 가 가능하다. 이것은 새로운 input인 특징(h)를 추가하면 특징에 맞는 output을 산출할 수 있다는 것이다.
새로운 input인 $h$ 가 추가적으로 들어왔을 때의 조건부 확률은 위의 수식을 따르게 된다. 이러한 상황은 예를들어 다중화자가 있는 환경에서, 우리는 화자를 한 명 선택하고 모델에 추가적인 input으로 화자의 특징을 전달하게 될 때 발생하게 된다. TTS에서 텍스트 정보를 추가적인 인풋으로 주는 것과 유사하다.
다른 인풋에 대한 모델의 조건부확률은 Global Conditioning 과 Local Conditioning 두 가지 방법으로 나눌 수 있다.
- Global Conditioning: 시점에 따라 변하지 않는 조건 정보를 추가하는 방법
- 모델로부터 여러 화자의 음성을 생성하고 싶을 때 사용하는 방법으로 화자의 특징(h)를 모든 시점에 동일하게 추가하여 모델을 학습시킨다.
- 화자의 특징은 timestep 별로 변하는 정보가 아니기 때문에 전역적으로 모든 시점에 영향을 주게 된다.
- Local Conditioning: 시점에 따라 변하는 조건 정보를 추가하는 방법
Context Stacks
Receptive Field를 증가시키는 방법으로
- Dilation 숫자를 증가시킴
- 더 많은 Layer 구성
- 더 큰 Filter 사용
- Dilation factor 증가
등이 있다.
이것을 보완하는 접근법이 바로 context stack이다.
Experiments
Multi-Speaker Speech Generation
단일 WaveNet이 여러 화자의 특징을 포함한 음성을 생성할 수 있는지를 검증함.
Text-To-Speech
Linguistic Features (음소, 음소길이, 주파수 등)을 추가로 학습한 후 HMM, LSTM-RNN Model과 비교.
Mean Opinion Score(MOS) Test 결과 압도적으로 WaveNet이 가장 높은 점수 획득.
Music
영어와 중국어 음악 데이터셋을 활용해 LSTM-Concat, HMM과 비교.
Speech Recognition
생성모델이지만 음성인식 과제로도 실험.
Conclusion
본 논문은 음성 파형 수준에서 직접적으로 음성을 생성하는 심층 생성 모델 WaveNet을 제안했다. WaveNet은 AutoRegressive하며 Receptive Fields를 확장시킨 Dialted Convolutions과 결합한 Causal Filters를 사용하고 있다. 여기에서 WaveNet이 입력에 따라 global (화자의 특징) 혹은 local (언어적 특징) 적으로 어떻게 조절되는지를 보여주었다. WaveNet을 TTS에 적용했을 때 현존 최고의 성능을 보여주었으며, Music과 Speech Recognition에도 매우 좋은 결과를 보여주었다.
