Transformer 소개
What makes sequential modeling a hard problem to handle?
문장은 항상 길이가 달라질 수도 있고 문장 어순을 바꾸는 등 문법에 항상 완벽하게 대응하는 문장을 만들지 않듯이 중간에 뭐 하나가 빠져있을 수 있음. 또한 permuted sequence라고 뭐 하나가 밀리거나 하는 등의 문제가 있을 수 있어서, 중간에 무언가가 바뀐 시퀀셜 데이터가 들어간다면 모델링이 굉장히 어려워진다. 이것을 해결하기 위해 Transformer가 등장하였고, self-attention 이라는 구조를 사용하게 된다.
Attention is all you need - Transformer is the first sequence transduction model based entirely on attention.
RNN이라는 구조에서 (하나의 입력이 들어가고, 다른 입력이 들어갈 때 이전 뉴런에서 가지고 있던 cell state가 다음 뉴런으로 들어가는 재귀적 구조) Transformer에는 재귀적인 구조가 없고, attention 구조를 활용했다는 것이 가장 큰 변화이다.
From a bird’s-eye view, this is what the Transformer does for machine translation tasks.
트랜스포머 방법론은 시퀀셜한 데이터를 처리하고 인코딩하는 문제이기 때문에 NMT에만 적용되지 않고, 이미지 분류, detection, 이미지분류, Dall-e(문장에 맞는 이미지 생성) 등 여러 태스크에서 활용되고 있다.
어떠한 문장이 주어졌을 때 (불어문장) 그것을 다른 문장으로 바꾸는 것을 하려고 하는 것임. 시퀀셜 데이터를 넣었을 때 시퀀셜 데이터가 나오게 하는 것.
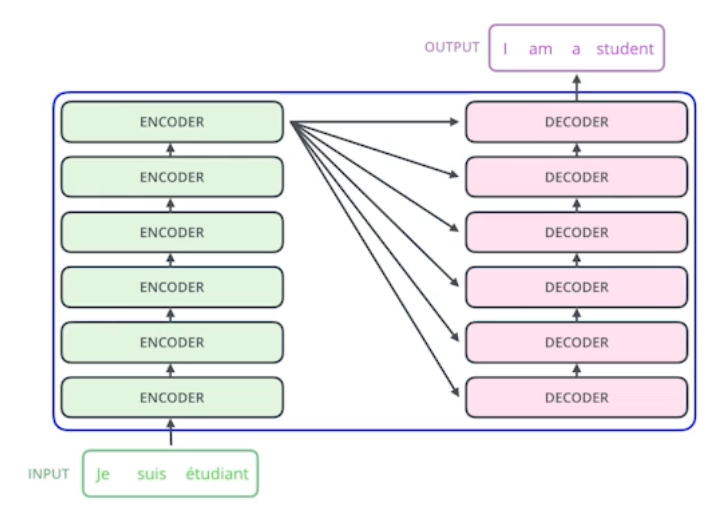
입력 시퀀스와 출력시퀀스의 단어 숫자가 다를 수 있고, 입력 시퀀스와 출력 시퀀스의 도메인이 다를 수 있는 하나의 모델구조임.
원래 RNN에서는 세 개의 단어가 들어가면 세 번의 작동을 했는데, 트랜스포머에서는 세 개든 백 개든 한 번에 인코딩을 할 수 있게 된다. 이렇듯 self-attention 구조에서는 n개의 단어를 한 번에 처리할 수 있다.
Six identical (but not shared) encoders and decoders are stacked. 동일한 구조를 갖지만 네트워크 파라미터가 다르게 학습되는 인코더와 디코더가 학습되어 있다.
그렇다면 n개의 단어가 어떻게 인코더에서 한 번에 처리되는가? 그리고 인코더와 디코더 사이에 어떤 정보들을 주고받는가? 마지막으로 어떻게 디코더가 generation 할 수 있는가?
인코더가 n개의 단어를 한 번에 처리할 수 있는 이유
n개의 벡터가 한 번에 들어가게 됨. 하나의 인코더는 Self-attention과 Feed Forward Neural Network 구조를 한 단 씩 거치는 구조로 되어있다. 그리고 출력되는 n개의 출력값이 두 번째 인코더의 input으로 들어가도록 stacked 되어 있다.
The Self-Attention in both encoder and decoder is the cornerstone of Transformer.
셀프어텐션은 트랜스포머가 왜 잘되게 되었는지를 나타낼 수 있다. 뒷단의 피드포워드 네트워크는 MLP와 사실 동일하기 때문이다.
Ex) NMT문제를 푼다고 가정을 하고, 3개의 단어만 들어온다고 가정을 해보자.
- 트랜스포머는 세 개의 단어가 주어지면, 세 개의 벡터를 각각 찾아주는 것이다. 여기서 중요한 점은 벡터에서 벡터로 가는게 하나의 피드포워드로 볼 수 있지만, 여기서 중요한 셀프어텐션은 하나의 벡터 x1->z1 과정에서 단순히 x1의 정보만을 활용하는 것이 아니라 x2, x3의 정보도 활용하는 것이다.
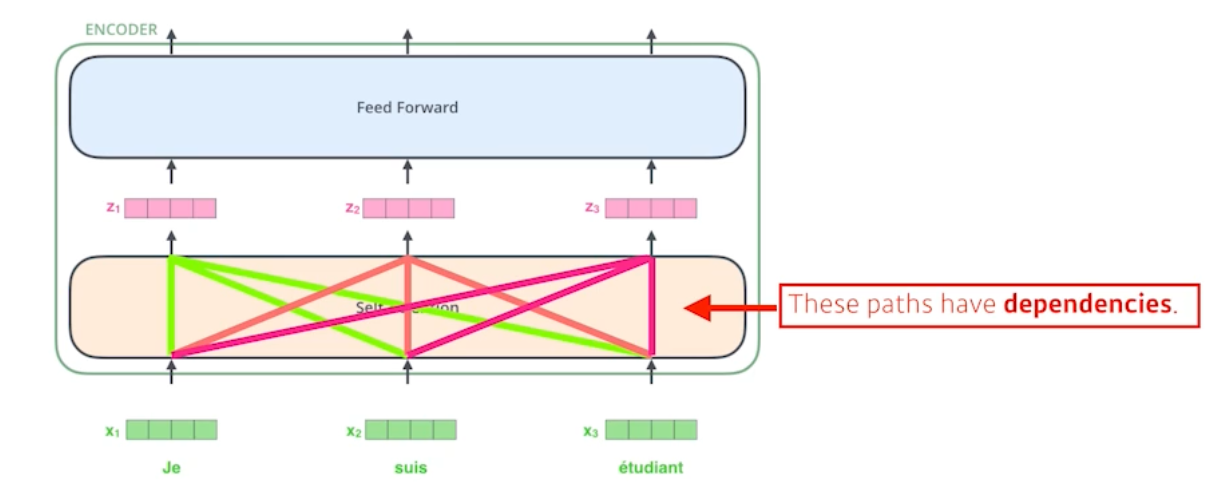
- 즉 n개의 단어를 만들 때 n개의 정보를 모두 활용하게 되고 피드포워드 네트워크는 디펜던시가 없이 그냥 변환해주는 것에 불과하다.
- Self-Attention at a high level.
- 하나의 문장에 있는 단어를 설명할 때는 단어를 그 자체만으로 이해하면 되는 것이 아니라 그 문장속에서 단어가 어떠한 interaction을 가지는지 알아야 한다.

트랜스포머는 위 사진의 it이 어떠한 단어들과 관계를 가지는지 계산하는 것이다.
기본적으로 Self-attention은 세 개의 벡터를 만들게 된다. (세 개의 뉴럴넷이 있다고 생각하면 됨) 그 벡터는 Q, K, V이며, 각각을 쿼리벡터 키벡터 밸류벡터라고 부른다.
Query, Key, Value vectors are computed per each word (=embedding). 하나의 입력이 주어졌을 때 하나마다 세 개의 벡터를 이루게 되고 이 세 개의 벡터를 통해 x1이라고 불리는 첫번째 단어에 대한 임베딩 단어를 새로운 벡터로 바꿔줄 수 있다.
각 단어마다 Q, K, V 벡터들을 만들었는데, 맨 처음에 하는 것은 Score 벡터를 만드는 것이다. 이 스코어 벡터를 계산할 때 인코딩을 하고자 하는 쿼리벡터와 나머지 n개의 키벡터를 구하고, 그 두 벡터를 내적한다. 즉 이 두 개의 벡터(쿼리, 키벡터)가 얼마나 align이 잘 되어있는지 보고 나머지 n개의 단어와 얼마나 유사도가 있는지 계산하게 된다.
내가 인코딩하고자 하는 쿼리벡터와 나머지 벡터들의 키 벡터를 전부 구한다음에 내적.
내적을 한 것은 결국에 R 번째 단어와 나머지 단어 사이에 얼마나 interaction 해야하는지를 알아서 학습하게 하는 것이고 이것이 결국 attention (특정 태스크를 수행할 때 특정 timestep에 어떤 입력들을 더 주의깊게 봐야할 지) 이다.
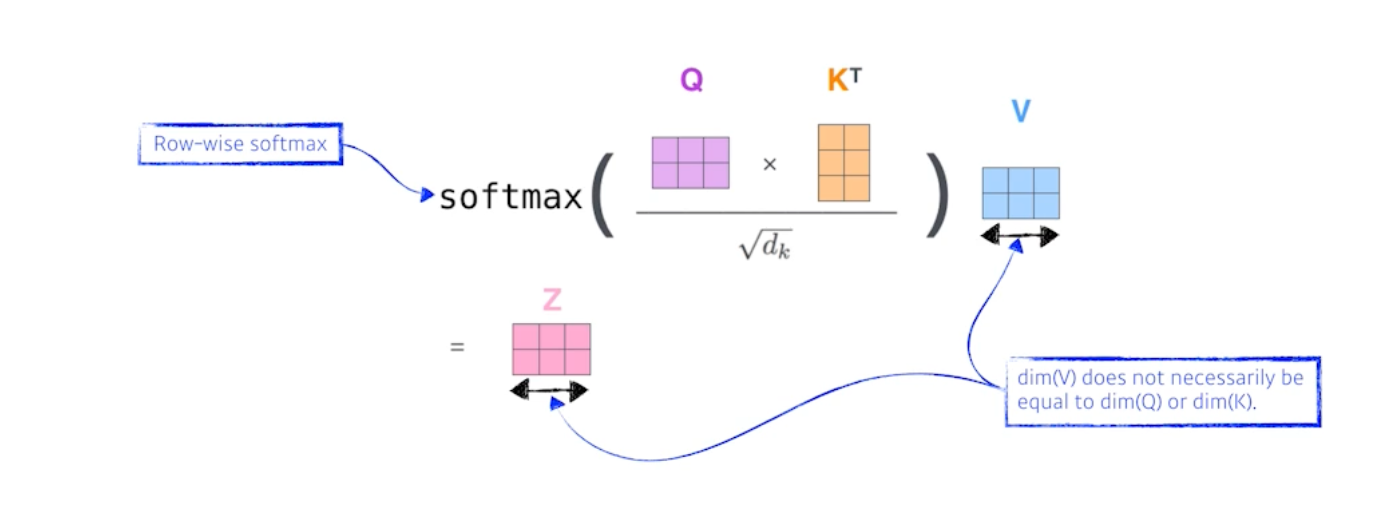
스코어벡터가 나오면 normalize하는데, key 벡터가 몇차원으로 할 지는 하이퍼파라미터고 키벡터 차원의 sqrt를 취해서 그것으로 나눠주게 된다. 스코어밸류 자체가 어떠한 range 안에 들어가게 하기 위해서 query 혹은 key 벡터 차원의 sqrt로 나눠주는 것이다. 그리고 score 벡터가 확률이 되게 하기 위해 softmax를 취해준다. 이렇게 attention weight를 구할 수 있음.
어텐션 웨이트는 각각 단어가 다른 단어, 혹은 자신 단어와 얼마나 Interaction을 해야하는가이고 이것은 스칼라로 나온다. 하지만 그 값이 어떤 값이 될지가 중요한데, 그것은 밸류벡터가 결정한다. 임베딩벡터가 주어지면 각각의 임베딩벡터마다 쿼리키밸류 벡터를 만들었고 그러고나서 나오는 키벡터와 밸류벡터의 내적으로 스코어벡터를 만들고, 소프트맥스를 취해 스칼라를 만든 이후 최종적으로 사용할 값은 각각의 단어 임베딩에서 나오는 밸류벡터들의 웨이트의 합이 되는 것임. 즉 밸류벡터들의 웨이트를 구하는 과정이 각 단어에서 나오는 쿼리벡터와 키벡터의 내적을 정규화하고 소프트맥스를 취하고 나온 attention을 밸류벡터의 웨이트 섬을 한 것이 임베딩벡터의 인코딩된 벡터가 되는 것임.
여기서 주의할 점은 Query 벡터와 Key 벡터의 차원은 항상 같아야한다. 하지만 Value 벡터의 차원은 달라도 된다. 밸류벡터는 결국 웨이티드 섬만 하면 되기 때문.
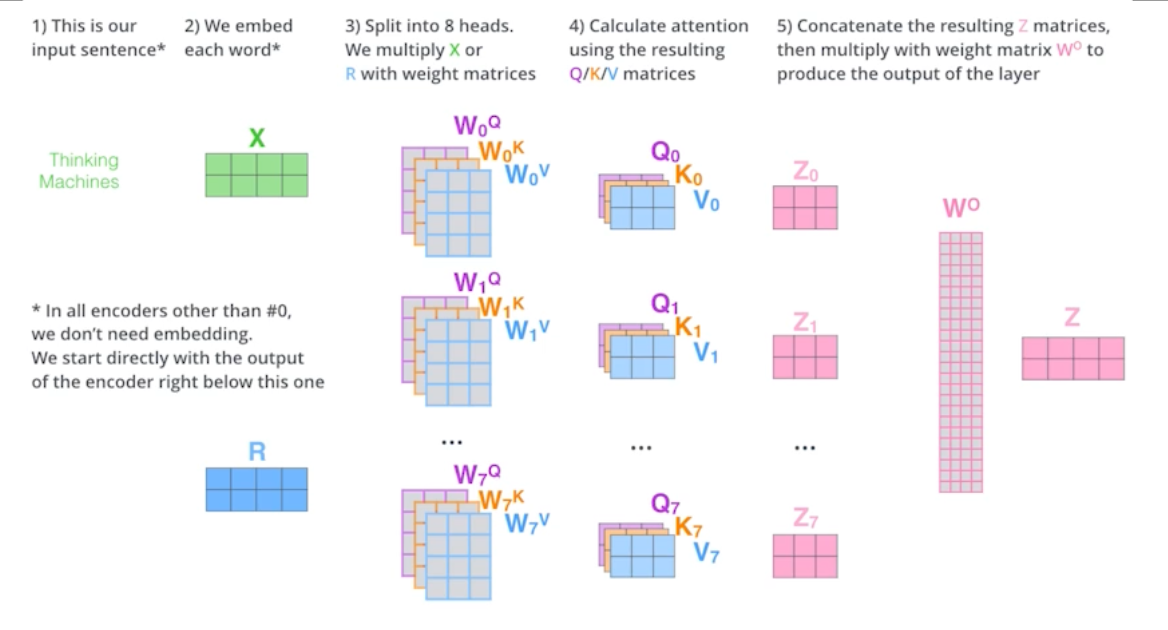
Multi-headed attention 은 앞에서 했던 어텐션을 여러 번 하는 것이다. (Q, K, V)를 n개 만드는 것이 멀티헤드어텐션임.
이렇게 함으로써 얻을 수 있는 것은 n 개의 어텐션을 반복하게 되면, n개의 인코딩 벡터가 나오게 된다.
여기서 중요한 것은 인코더가 하나만 있는데 인코딩된 벡터가 다음으로 넘어갈 때 필요한 것은 입출력 차원이 맞아야한다. 임베딩된 디멘젼과 인코딩되서 셀프어텐션으로 나오는 벡터가 항상 같은 차원이어야 한다.
Positional Encoding
- 입력에 특정 벡터값을 더해주는 bias이다.
- 필요한이유: 트랜스포머는 n개의 단어를 sequential 하게 넣어줬다고 하지만, 실질적으로 sequential한 정보가 사실은 포함되어 있지 않다. abcd, bcda, cdba 등의 각각 단어들이 인코딩되는 값은 달라질 수가 없다. order에 의존적이지 않기 때문이다. 실제로 문장을 만들 때 어떤 단어가 먼저 나왔는지는 중요하지 않다. 따라서 포지셔널 인코딩이 필요하게 된다.
Self-attention으로 n개의 단어가 주어지면 n개의 단어가 나타나는데, i번째 단어를 인코딩할 때 나머지 n개의 모든 입력 정보를 활용하여 각각의 단어들에 대하여 인코딩 벡터를 찾는다.
즉 encoder 안에서는 self-attention, residual-connection, normalize, feed-forward 의 순서로 각각의 인코딩된 벡터에 대해서 독립적으로 동일한 뉴런네트워크가 동작하게 된다.
Encoder는 주어진 단어를 표현하는 것이었고 디코더는 그것을 가지고 무언가를 생성하는 페이즈다.
Decoder에서는 어떤 벡터가 인코더에서 전해졌는지가 중요하다. Transformer는 결국에 Key와 Value를 보내게 된다. i번째 단어의 쿼리벡터와 나머지 단어들의 키벡터를 곱해서 어텐션을 만들고 거기에 밸류벡터의 웨잍섬을 하는데, input을 디코더에서 출력하고자 하는 단어들에 대해서 만드려면, Key벡터와 Value벡터가 필요하고, 가장 상위 단어들의 레이러를 만들게 된다. 디코더에 들어가는 단어들로 만들어지는 쿼리벡터와 인코더(입력)으로 주어지는 벡터를 가지고 최종값을 만들어내는 것이다. 그리고 최종 출력은 autoregressive 하나의 단어씩 만들게 된다.
In the decoder, the self-attention layer is only allowed to attend to earlier positions in the output sequence which is done by masking future positions before the softmax step.
The Encoder-Decoder Attention layer works just like multi-headed self-attention, except it creates its Queries matrix from the layer below it, and takes the Keys and Values from the encoder stack.
The final layer converts the stack of decoder outputs to the distribution over words.
Vision Transformer (ViT)
트랜스포머는 이미지에도 활용되고 있는데 이미지 분류를 할 때 인코더만 활용하고 인코더 벡터를 트랜스포머에 집어넣는 식으로 동작한다. 이미지를 특정 영역으로 나누고 각각 영역에 sub patch들을 linear layer에 넣어서 시퀀셜한 데이터처럼 활용한다.
즉 Transformer는 단순 NMT, NLP 에만 활용되는 것이 아니라 비전에도 활용되고 있다.
DALL-E
텍스트->이미지
트랜스포머의 디코더만 활용을 했고 이미지도 그리드로 나눠서 시퀀스로 활용했고 문장 역시 시퀀스로 활용했다.
GPT-3 를 활용했다고 함.
Transformer 소개
