RNN 소개
Sequential Model
- 일상에서 다루는 대부분의 데이터가 시퀀셜 데이터다. (말, 영상 등)
- 시퀀셜 데이터를 다루는 가장 큰 어려움은, 우리가 가장 얻고 싶은 것은 어떤 영역에 어떤 정보가 있다와 같은 것인데, 시퀀셜 데이터는 길이가 얼마나 될지 모르는 것이다. 즉 데이터가 몇개의 차원으로 되어있을지 모른다는 것인데, 이것은 시퀀셜 모델은 몇 개의 데이터가 들어오든 동작할 수 있어야 한다.
- 이전에 어떤 데이터가 들어왔을 때 다음에 어떤 데이터가 들어올 지 예측하는 것이 가장 기본적인 모형이다.
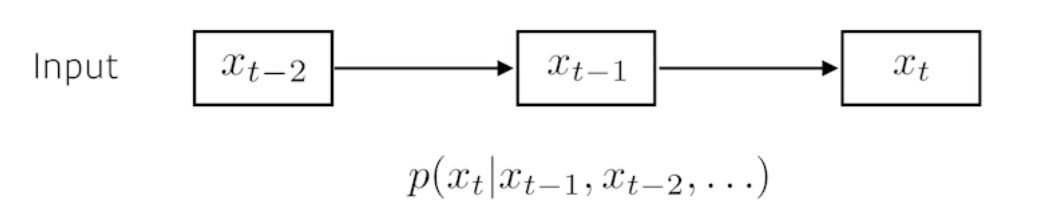
- 과거에 고려해야 하는 정보량이 계속 늘어난다는 것이 가장 큰 어려움이다.
시퀀셜 모델을 가장 간단히 만들 수 있는 방법은, Fix the past timespan 과거의 데이터를 몇 개만 보겠다고 정해두는 것이다.
- Autoregressive model
- Markov model (first-order autoregressive model) 가장 큰 특징은 가정을 할 때 바로 이전 과거에만 dependent 한다는 것이다. 이러한 마르코프 모델은 과거의 많은 정보를 버릴 수밖에 없다는 단점이 있다.
Latent autoregressive model
- 위의 모델들은 과거의 많은 정보를 사용할 수 없기에 대안으로 나온 것이 Latent autoregressive model이다.
- 중간에 Hidden state가 들어가 있는데, 이것은 과거의 정보를 요약하고 있다고 생각하면 됨.
- 즉 바로 직전 과거에 의존하는 것이 아닌 hidden state에 의존하는 구조이다.
Recurrent Neural Network
자기 자신으로 돌아오는 구조가 하나 있다. 나의 h_t 에서의 t에서의 hidden state는 x_t에 의존하는 것이 아니라 t - 1에서 얻어진 cell state에 의존하는 구조임.
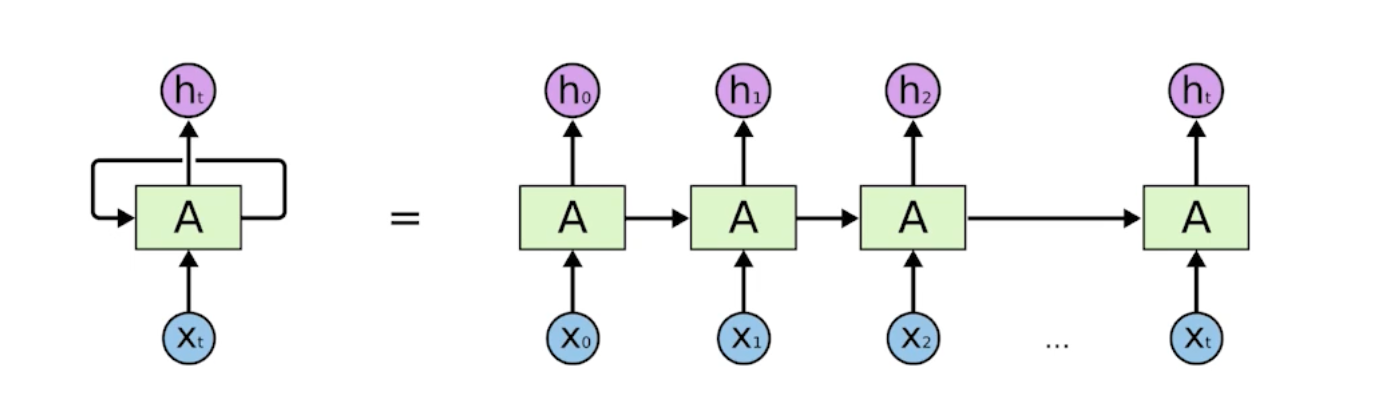
Recurrent 구조를 시간순으로 풀게 되면 입력이 많은 FC Layer로 표현할 수 있다.
Short-term dependencies
- 과거에 얻어진 정보들이 전부 취합되어서 미래에 고려해야 하는데 RNN 자체는 하나의 Fixed Rule로 하나로 취합하기 때문에 과거의 정보가 현재까지 살아남기가 힘들어진다.
- 즉 불과 몇 스텝 전의 정보는 잘 고려가 되는데 한참 전의 정보는 잘 고려가 되지 않는다.
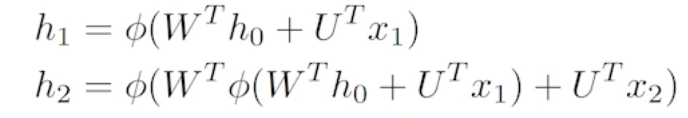
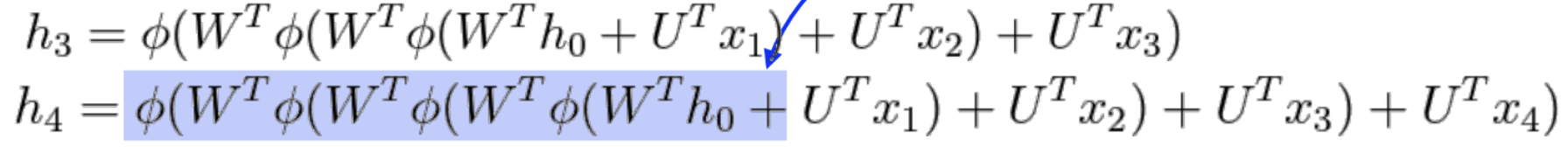
- 활성화함수가 sigmoid 인 경우 Vanishing(기울기소실) 문제, ReLU일 때는 exploding gradient(기울기폭발) 문제가 발생한다.
Varnila RNN
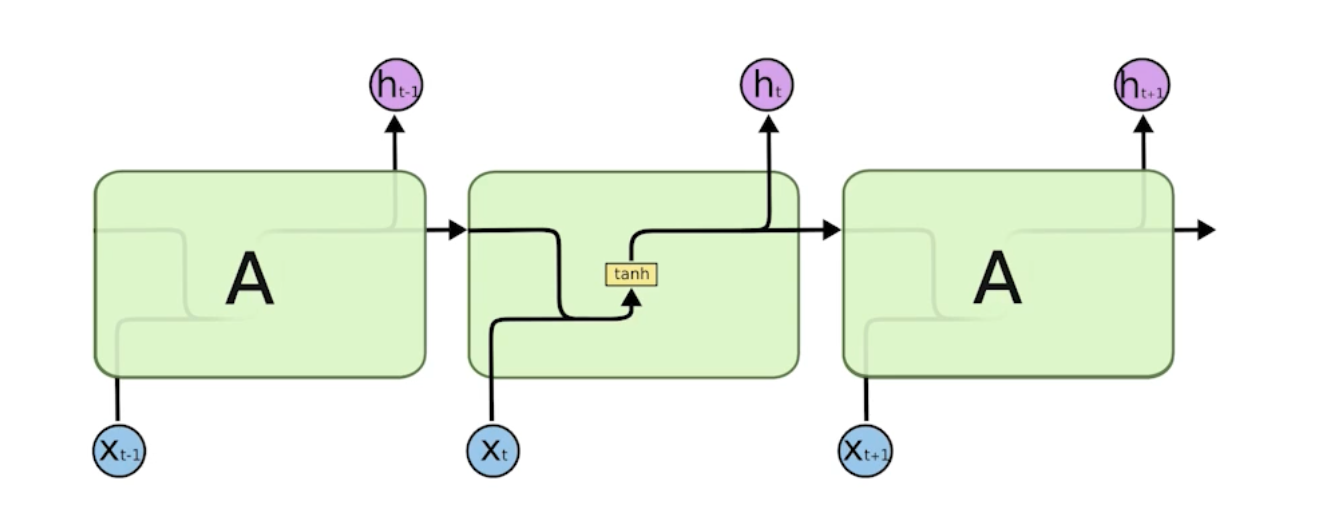
LSTM (Long Short Term Memory)
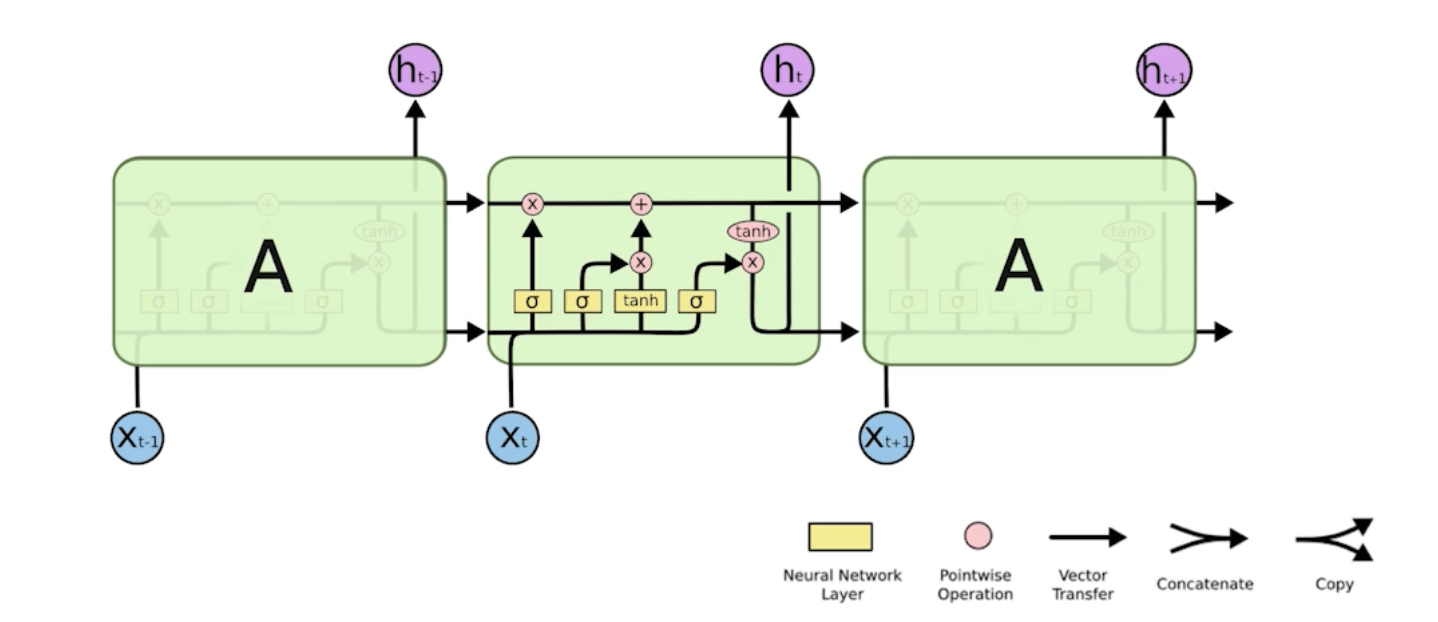
- cell state는 내부에서만 흘러가고 t + 1개의 정보를 summarize 해준다.
- output이 아래로도 흐르는데, 이 output은 previous hidden state로 t+1로도 흐르게 된다.
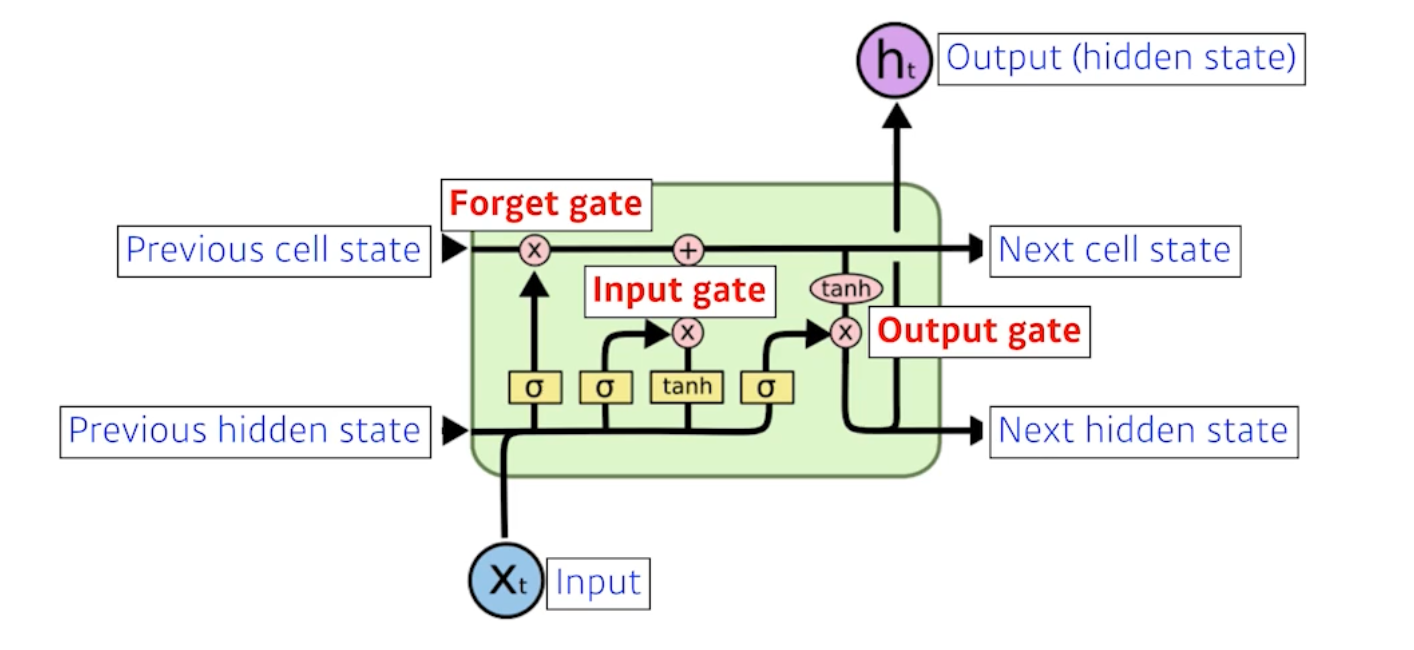
Forget gate
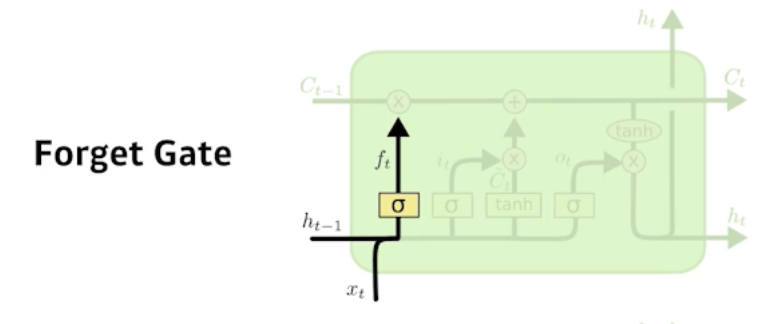
중간에 흘러가는 cell state가 핵심이다.
흘러가는 컨베이어 벨트처럼, 어떤 물건을 올리고 빼고 결정하는 것이 Cell State로 Forget Gate의 역할이다.
Decide which information to throw away.
$f_{t}=\sigma\left(W_{f} \cdot\left[h_{t-1}, x_{t}\right]+b_{f}\right)$
Input gate
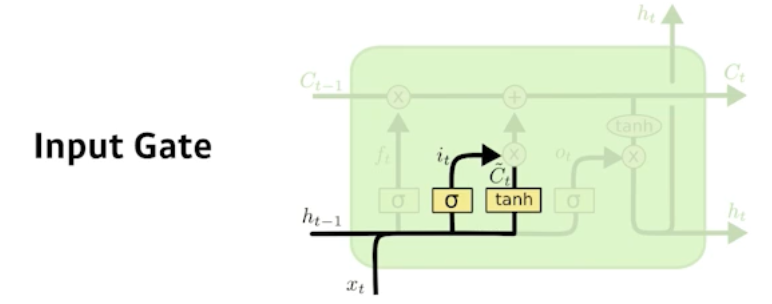
- $\begin{aligned}
i_{t} &=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\
\tilde{C}_{t} &=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)
\end{aligned}$ - Decide which information to store in the cell state.
Update cell
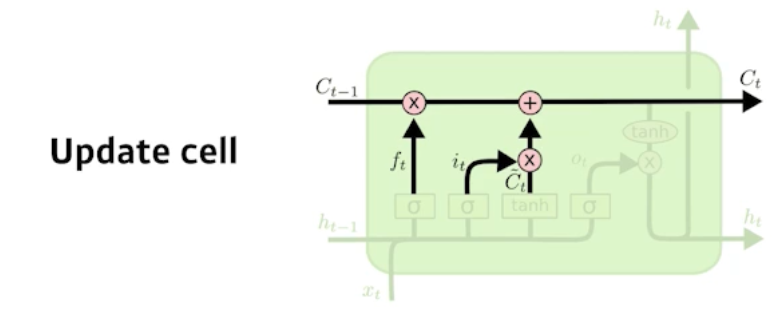
- Update the cell state.
- $\begin{aligned}
i_{t} &=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\
C_{t} &=f_{t} C_{t-1}+i_{t} \tilde{C}_{t}
\end{aligned}$
Output gate
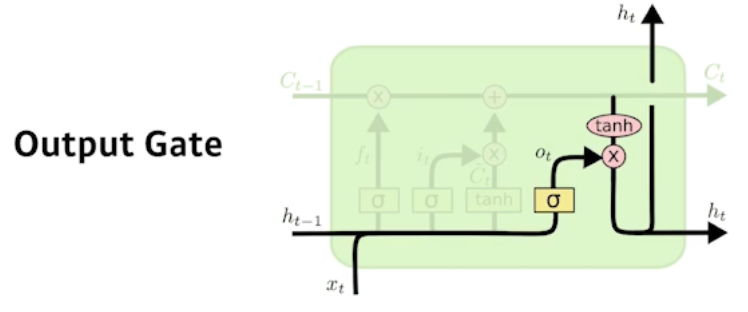
- Decide which information to store in the cell state.
- $\begin{aligned}
i_{t} &=\sigma\left(W_{i} \cdot\left[h_{t-1}, x_{t}\right]+b_{i}\right) \\
\tilde{C}_{t} &=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)
\end{aligned}$
GRU (Gated Recurrent Unit)
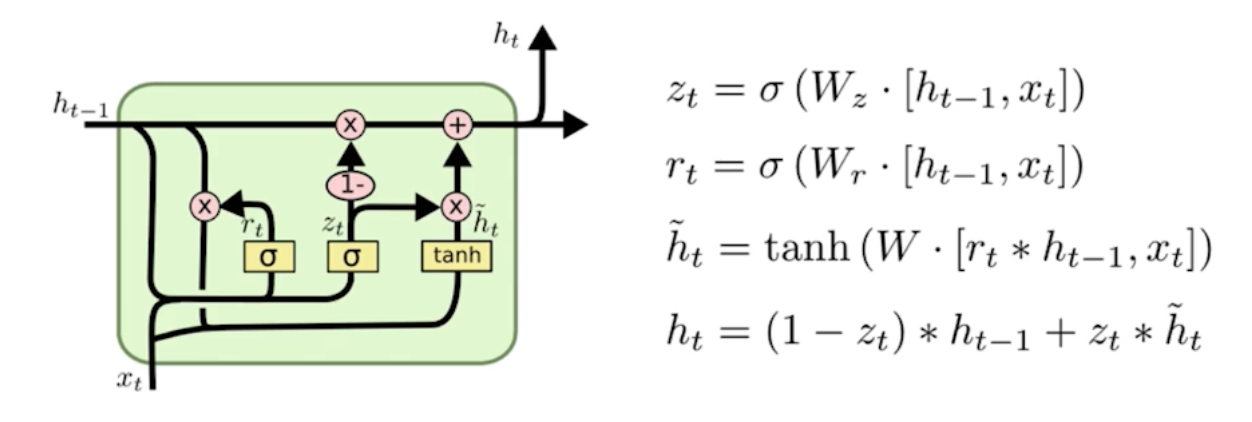
게이트가 두 개임. (reset gate & update gate)
cell state가 없고 hidden state만 있음.
LSTM보다 GRU의 성능이 높은 경우가 있음. 하지만 Transformer 등장 이후엔 둘 다 잘 쓰지 않음.
