Optimization 소개
“Language is the source of misunderstandings” - Antoine de Saint-Exupery (1900-1944)
용어에 대한 정리를 하고 넘어가야 이후에 오해가 생기지 않는다. 용어 통일이 가장 중요하기 때문에 용어에 대한 명확한 컨셉을 잡아볼 것임.
Introduction
Gradient Descent
- First-order iterative optimization algorithm for finding a local minimum of a differentiable function.
- 찾고자 하는 파라미터에 대해서 손실함수를 미분한 편미분값을 가지고 학습을 하겠다는 것임.
- Local minimum: 손실함수를 미분했을 때 극소적으로 좋은 로컬 미니멈을 찾는 것을 목적으로 함.
Important Concepts in Optimization
Generalization (일반화)
- 대부분의 경우 일반화 성능을 높이는 것이 목적이다.
- 일반화 성능을 높이기만 하면 좋은 것인가?
- 일반적으로 학습을 시키게 되면 Iteration이 지나면서 Training Error를 줄이게 되는데, Training Error가 0이 되었다고 해서 우리가 항상 원하는 최적값에 도달했다는 보장이 없다.
- 일반적으로 Training error가 주어지지만, 어느정도 시간이 지나고 나면 Test Error가 커짐, 즉 학습에 사용하지 않은 데이터에 대해서는 성능이 오히려 떨어지게 된다.
- 즉, 일반적으로 일반화는 테스트에러와 트레이닝 에러의 갭을 줄이는 것을 의미한다.
- 만약 우리 네트워크가 안좋아서 학습데이터에 대한 성능이 안좋으면, 일반화의 퍼포먼스가 좋다고 해서 테스트 데이터의 성능이 좋다고 말할 수 없다.
- 일반화의 성능은 테스트와 트레이닝 에러의 갭을 말하기 때문이다.
Under-fitting vs. over-fitting
학습데이터에 대해서는 잘 동작을 하지만 테스트데이터에 대해서 잘 동작하지 않는 것을 OverFitting이라고 한다.
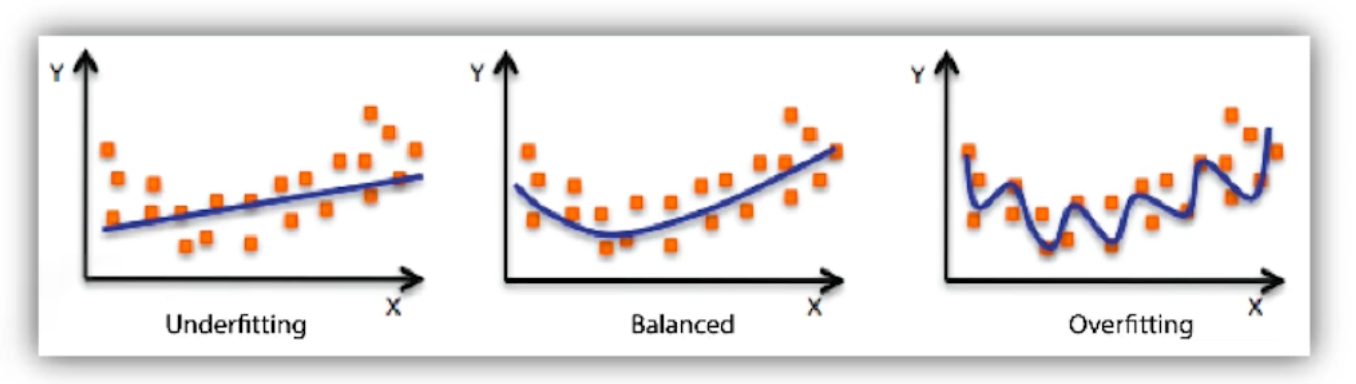
Cross validation
- 일반적으로 데이터가 분리되어 있음 (Train, Test, Validate)
- 보통은 학습 데이터로 학습시킨 모델이 학습에 사용되지 않은 밸리데이션 데이터를 기준으로 학습이 잘 되었는지 확인하는 과정이다.
- 하지만, 트레인과 테스트를 반반으로 했을 때, 트레인을 80 테스트를 20으로 했을 때 등 Split 범위에 따라서 학습의 퍼포먼스가 달라질 수 있다. 이러한 것을 해결하고자 하는 것이 Cross Validation이다. (혹은 K-Fold Validation)
- 네트워크를 학습할 때 수많은 파라미터가 존재한다. 또한 Hyper Parameter들에 대한 기준이 없다. 따라서 Cross-validation을 통해 최적의 Parameter Sets 을 찾고, 파라미터를 보정한 상태에서 모든 학습데이터를 학습에 사용해야 더 많은 데이터를 사용할 수 있다.
- Test Data는 어떠한 방법으로든 학습에 사용되어서는 안된다. 즉, 학습에는 Train과 Validate 데이터만을 이용해야 한다.
Bias-variance tradeoff
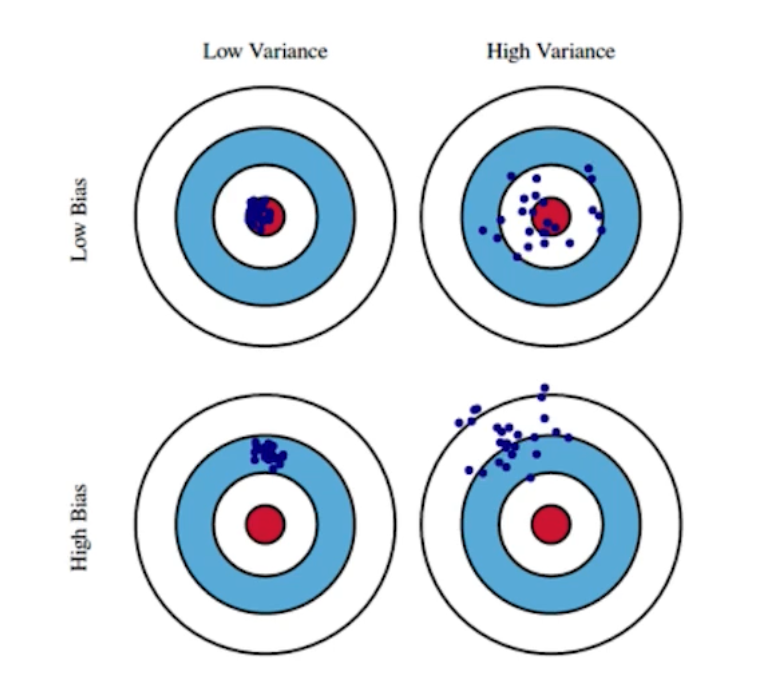
사격을 할 때 항상 같은 곳에만 찍히면 (원점이 아니더라도) 좋은 것이다. 전체 모델을 어느정도 평준화 시키면 최적값에 도달할 가능성이 많기 때문이다. 이것을 Low Variance라고 한다. (출력이 얼마나 일관적으로 나오는 지)
이것에 반해 Variance가 크면 비슷한 입력이 들어와도 출력이 많이 달라지는 것을 의미한다.
Bias라는 것은 출력에 따른 평균적으로 True Target에 접근하는 정도를 의미하며, Bias가 크면 Mean에서 많이 벗어나는 것을 의미한다.
학습 데이터에 Noise가 껴있다고 가정했을 때 내가 이 노이즈가 껴있는 타겟 데이터를 미니마이즈하는 것에 대하여 세 파트로 나뉘어진다. 내가 미니마이즈하는 것은 하나의 값(cost)이지만, 그 값은 세 파트로 나뉘어져 있어서 한 파트를 줄이면 다른 파트가 커질 수밖에 없는 Trade-off 관계이다.
위 식에서 cost를 minimize한다는 것은 bias와 variance, noise를 minimize 한다는 것을 의미한다.
Bootstrapping
- 신발끈을 말하는 것이며, 그 뜻은 신발끈을 들어올려 하늘을 날겠다라는 허황된 뜻임.
- 딥러닝에서는 학습 데이터가 100개가 있다고 하면, 100개 중 80개를 사용하겠다 등 일부만 뽑아서 사용한다는 것을 의미한다.
- 이렇게 했을 때 하나의 입력에 대해서 각 모델들의 출력이 달라질 수 있다. 이 때 각 모델들의 예측값들이 얼마나 일치를 이루는지 보고 전체 모델들의 특성을 알고자 하는 것이다.
- 학습데이터가 고정되어 있을 때 subsampling을 통해 여러 학습데이터를 만들고 그것을 이용하여 여러 모델 혹은 metric을 만들겠다는 것임.
Baggin and boosting
- Bagging(Bootstrapping aggregating)
- 학습데이터를 여러 개를 만들어서 (Booststrapping) 여러 모델을 만들고 그 모델의 output들을 가지고 평균을 내겠다는 뜻임.
- 학습데이터가 고정되어 있으면 이것을 모두 이용하여 하나의 결과를 내는 것이 좋을 것 같지만 사실은 그렇지 않다. N개의 모델을 만들고, N개의 모델의 출력값의 평균이나 Voting을 통해 나오는 결과를 사용하는 것이 보통 성능이 더 좋다.
- Boosting: 학습데이터를 시퀀셜하게 바라봐서 간단한 모델을 만들고, 모델에 학습데이터를 다 넣어본다. 모델에서 80개는 잘 예측을 했지만 20개는 잘 안되었다. 이 때 모델을 하나를 더 만드는데 전에 안되었던 20개에 데이터를 잘 예측하는 모델을 만든다. 이렇게 모델들을 만들고 합친 이후에 하나의 struct learner를 만들고, 그 weight를 찾는 방식을 말한다.
Practical Gradient Descent Methods
Stochastic gradient Descent
- 하나의 샘플을 이용
Mini-batch Gradient Descent
- Subset of data 를 사용
Batch Gradient Descent
- whole data 를 사용
Batch-size Matters
배치사이즈는 굉장히 중요하다.

엄청나게 큰 배치를 사용하게 되면 Sharp Minimizers에 도달한다. 하지만 작은 배치를 사용하면 Flat Minimizers에 도달한다.
배치사이즈를 작게 사용하는 것이 일반적으로 좋다. sharp보단 flat이 더 좋다는 것임.
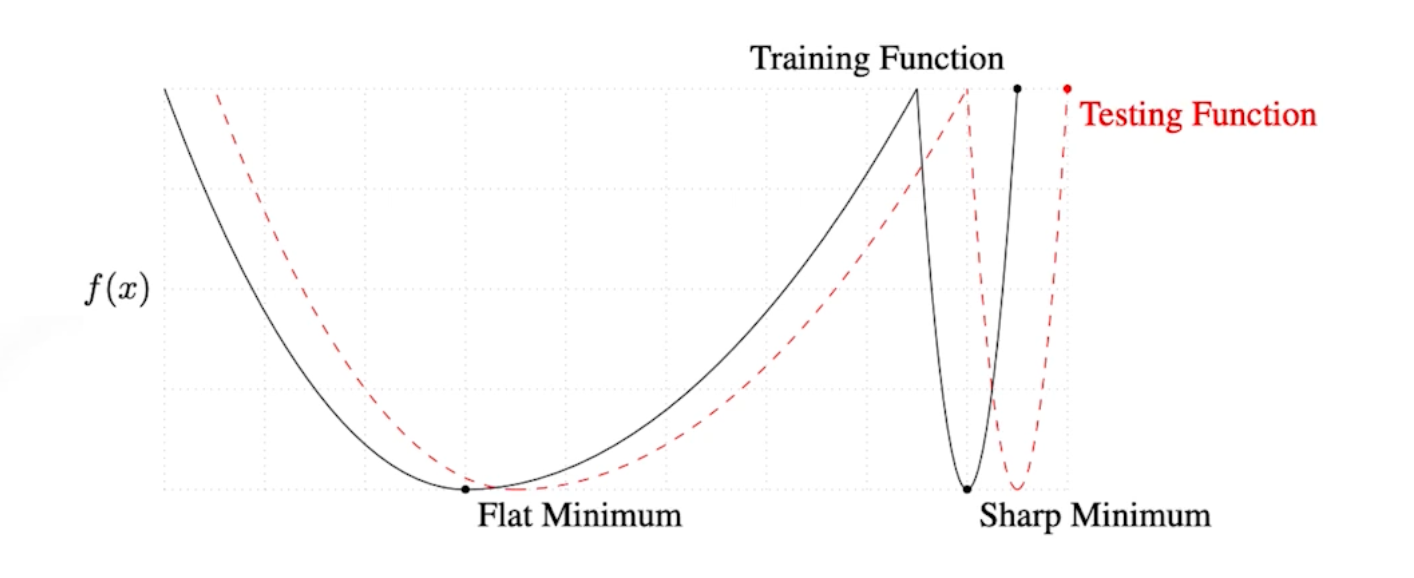
우리의 목적은 Train function에서 잘 동작하는 것이 아니라 Testing function에 잘 동작하는 것이다. 이 때 Flat Minimum은 Testing 값이 잘 나오지만, Sharp Minimum의 경우 한 번도 트레인에 사용되지 않은 데이터에서는 잘 동작하지 않는다.
Gradient Descent Methods
구현할 필요는 전혀 없음! 딥러닝 프레임워크에서는 한 줄 컷이다.
Stochastic Gradient Descent
- 가장 큰 단점은 Lr, stepsize를 잡는 것이 가장 어렵다는 것이다. 너무 크면 학습이 안되고, 너무 작으면 학습을 오래 시켜도 학습이 안된다.
- $W_{t + 1} \leftarrow W_t - \eta g_t$
- $\eta$ : Learning rate or step size
- $g_t$: Gradient
Momentum (관성)
SGD의 단점을 극복하기 위해 제시된 Optimization 테크닉이다.
한 번 Gradient가 한 방향으로 흐른 이후 다음 Gradient 가 조금 다른 방향으로 흘렀어도, 이전 방향으로 흘렀던 정보를 활용해보자.
$a_{t+1}$ : Accumulation
$\beta$ : Momentum
모멘텀과 현재 기울기를 합친 Accumulation으로 Update를 한다.
장점은 한 번 흘러간 기울기를 포함하여 업데이트를 하기 때문에 어느정도 학습이 잘 이루어지게 된다.
Nesterov Accelerated Gradient
이것도 역시 a라고 하는 Accumulate 가 업데이트를 하는 것인데, 기울기를 계산할 때 Lookahead gradient를 계산하게 된다.
모멘텀은 이전 기울기 정보로 계산하는데, 이 친구는 a라고 하는 현재 정보가 있다면 그 방향으로 한 번 가보고 기울기를 계산한 다음에 그 기울기를 가지고 Accumulation을 계산한다.
일반적으로 모멘텀을 관성으로 해석한다면, Local Minimum으로 Conversion 하지 못하는 현상이 생길 수 있는데 이에 반해 NAG는 Local Minimum을 지나서 기울기를 계산하는 것이 아니라 한 번 지나간 그 점에서 기울기를 계산하는 것이기 때문에 Local Minimum이 한 쪽 아래로 흘러갈 수 있다는 장점이 있다. 즉, 극값에 조금 더 빠르게 접근할 수 있다는 장점이 있다.
Adagrad
- 신경망의 파라미터가 변했는지 안변했는지를 보게 되고 많이 변한 파라미터들은 적게 변화시키고 조금 변한 파라미터는 많이 변화시키기 위해 고안된 Adaptive Learning 이다.
- 즉 파라미터들이 얼마나 변했는지를 기록한 정보가 필요하다.
- $W_{t+1}=W_{t}-\frac{\eta}{\sqrt{G_{t}}+\epsilon} g_{t}$
- $G_t$: sum of gradient squares
- 가장 큰 문제는 $G_t$ 라는 것이 계속해서 커지기 때문에 결국에는 무한대로 가게 되면 분모가 무한대니까 W의 업데이트가 안되게 된다. 즉 뒤로 갈 수록 학습이 점점 되지 않는 문제가 생긴다. 이것을 해결하기 위해 고안된 방법이 Adam 등이다.
Adadeltha
Adagrad가 가지는 $G_t$가 커지는 것을 막기 위해 고안된 방법 중 하나이다.
타임스텝 t가 주어졌을 때 $G_t$ 를 윈도우 사이즈 만큼의 파라미터, 시간에 따른 기울기 변화를 보겠다는 것임.
이것 역시 문제가 있음. 윈도우 사이즈를 100으로 잡았을 때 100회 정보에 대한 값을 가지고 있어야 한다. 즉 GPU가 터질 수도 있다. 이것을 $H_t$ 를통해 해결할 수 있다.
Adadelta의 가장 큰 특징은 Learning rate가 없다는 것인데, 그 뜻은 우리가 무언가를 시도해볼 것이 적다는 뜻이다. 따라서 잘 쓰이지 않는다.
RMSprop
논문을 통해서 제안된 방법이 아니다.
아이디어는 간단함.
Adagrad 처럼 Gradient Squares를 그냥 더하는 것이 아니라 분모에 넣고, $\eta$ 라는 stepsize가 들어간다.
Adam
일반적으로 가장 무난하게 사용하는 것이 바로 Adam이다.
$m_t$ : momentum
$v_t$ : EMA of gradient squares
Gradient 크기에 따라서 Adaptive하게 Learning rate를 바꾸는 것과 이전 Gradient 정보에 해당하는 모멘텀을 잘 합친 방법이다.
Regularization
학습에 잘 되는 것을 방해하기 위해 규제하는 것임. 학습을 방해함으로써 얻기 위한 목적을 잘 생각해야 한다. 즉, 학습데이터가 잘 되기 위해 사용하는 것이 아니라 방해함으로써 테스트데이터에도 잘 동작하도록 만드는 것이다.
Early stopping
- 학습을 일찍 멈추는 것. 하지만 학습을 멈출 때 테스트 데이터를 사용하면 Cheating이기 때문에 Validation Data를 사용한다.
- Loss 가 어느 순간부터 커질 수 있는 데 그 시점에 빠르게 학습을 멈추자는 것임.
Parameter norm penalty
- 신경망 파라미터가 너무 커지지 않게 하는 것임. 각 파라미터들을 제곱한 다음에 더하면 어떤 숫자가 나올텐데, 그 숫자를 같이 줄이는 것이다.
- 이왕이면 네트워크 웨이트의 숫자가 작을 수록 좋다. ‘크기’에 관점에서.
- 물리적이거나 해석적인 관점에서의 의미는 뉴럴넷이 만드는 함수의 공간속에서 함수를 최대한 부드러운 함수로 보자는 것이다. 부드러운 함수일수록 일반화 성능이 높다는 것일 것이다라는 가정이 전제됨.
Data augmentation
딥러닝에서 가장 중요한 것 중 하나가 데이터이다.
데이터가 적으면 딥러닝보다 전통적인 ML(XG Boost, Random Forest 등)이 훨씬 성능이 높다.
하지만 데이터가 커질수록 머신러닝 방법론들보다 딥러닝 방법론이 훨씬 성능이 좋다.
하지만 데이터는 한정적이기 때문에 Augmentation을 통해 어떠한 방법으로든 데이터를 늘리는 것이다.
Noise robustness
- 왜 잘되는지는 아직 의문이 있다.
- Data Augmentation이랑 비슷할 수도 있지만, 데이터에 노이즈를 집어넣는 방식이다. 굳이 차이를 두자면 입력에만 노이즈를 두는 것이 아니라 weight에도 noise를 주는 것이다.
Label smoothing
- 데이터 두 개를 뽑아서 Train 단계의 데이터 두 개를 섞어주는 것이다.
- 일반적으로 분류 문제에서 Descision Boundary를 찾는 것이 목적인데, Descision Boundary 를 조금 더 부드럽게 만들어주는 효과가 있다.

- 라벨을 섞고 이미지(학습데이터)도 섞는 방법임.
- 왜 잘되는지가 설명되기 보다는 그냥 하면 잘 된다.
Dropout
- 신경망의 weight를 0으로 바꾸는 것이다.
- 각각의 뉴런들이 더욱 Robust한 Feature를 얻을 수 있다고 해석을 한다.
Batch normalization
- 논란이 많은 논문이다.
- 적용하려는 레이어에 Statistics를 정규화 시키는 것이다.
- 천개의 파라미터가 있는 히든레이어라면, 천개의 파라미터의 각각의 값들에 대한 statistics에 대해 평균을 빼주고 표준편차를 나눠주는 방식이다.
- 활용하면 성능이 많이 올라간다.
Optimization 소개
