Convolution 소개
파라미터 수 손으로 직접 계산해보기
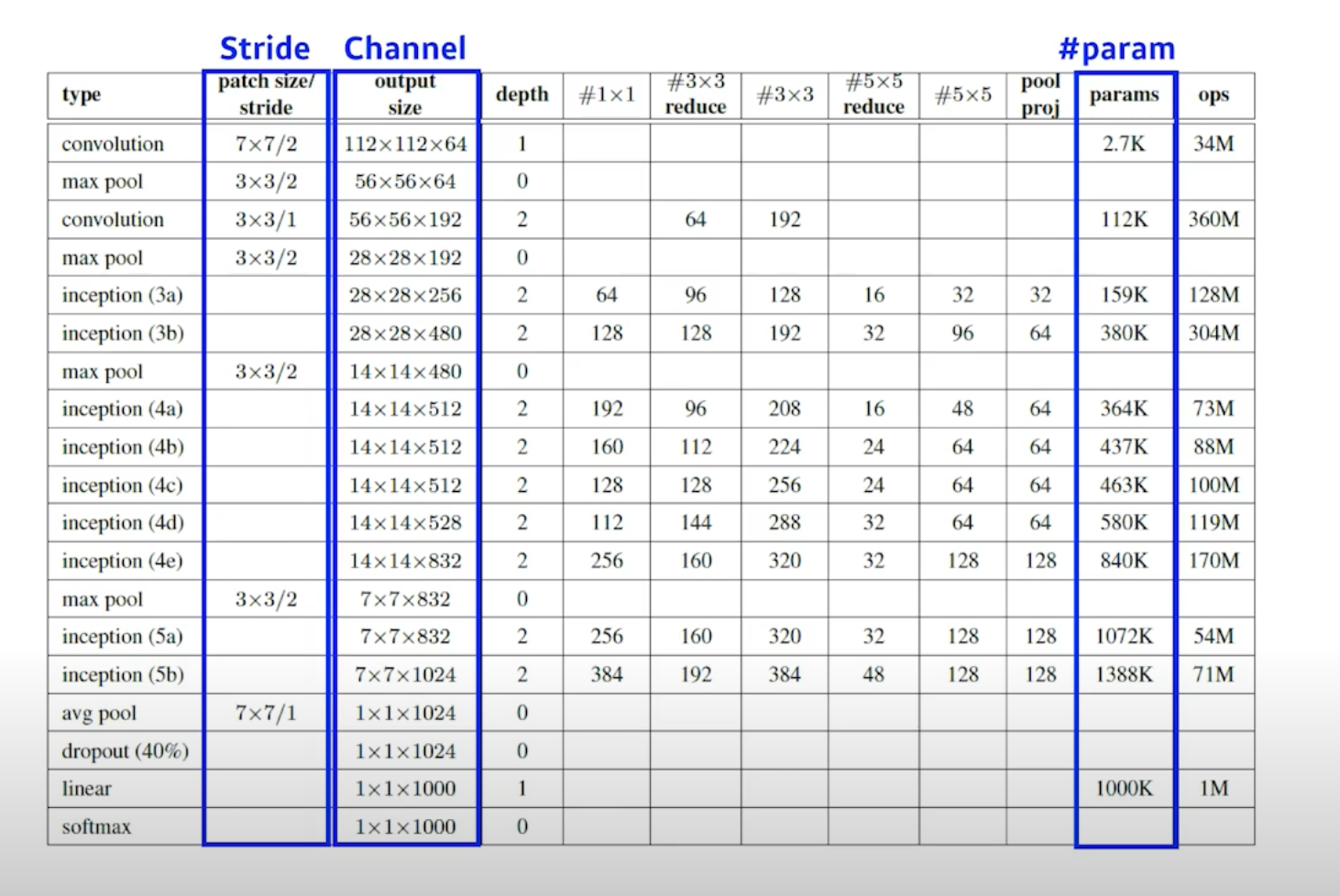
알렉스넷의 파라미터 수 구하기
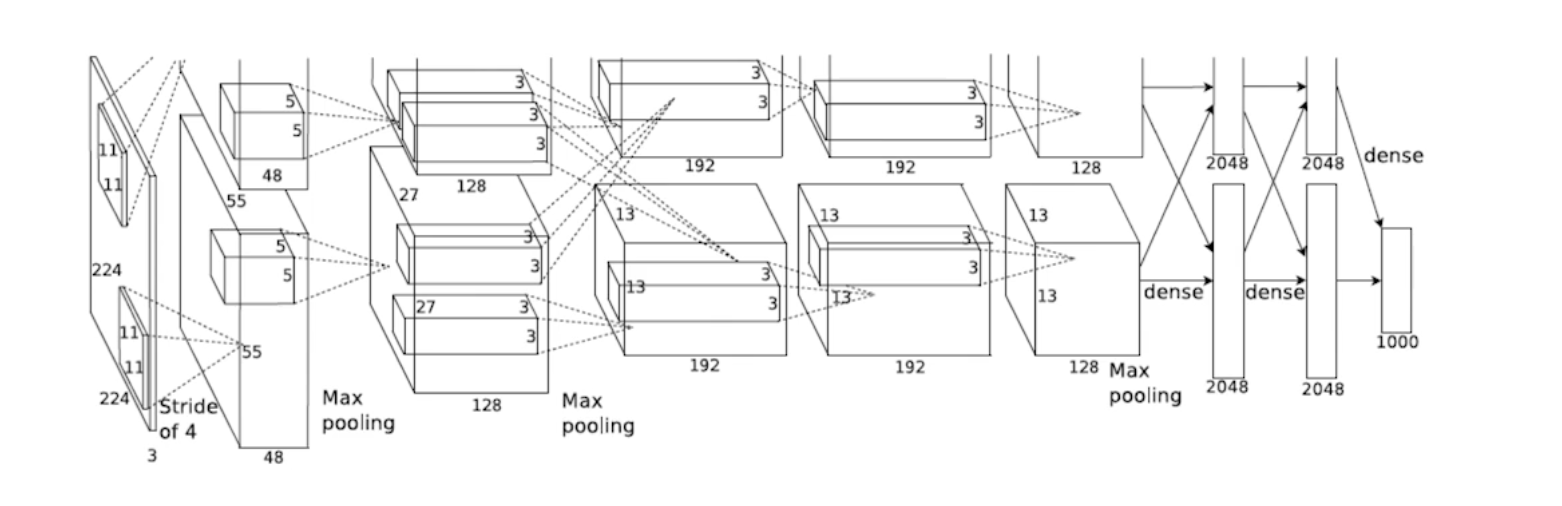
input = 224 224 3
filter = 11 11 3
fisrt param = $11113482 ~= 35k$
Modern CNN
AlexNet
네트워크가 두 개로 나뉘어져 있다. 당시 GPU가 부족했기 때문임. 두 장의 GPU로 학습하고 합쳤다. 인풋에 $11 * 11$ 필터를 사용했는데, 파라미터 관점에서 좋진 않다. 상대적으로 많은 파라미터가 필요하기 때문. 이후 5개의 Convolution 레이어와 3개의 Dense 레이어를 사용한다. 최근 200-300개 네트워크를 가진 신경망에 비하면 Light한 편이다.
Key Ideas
- Rectified Linear Unit(ReLU) 활성화 함수를 사용했다. $ReLU = max(0, x)$
- 리니어 모델이 갖는 좋은 성질들을 가질 수 있게 한다.
- 리니어 모델들의 성질을 가지고 있기 때문에 학습하는 SGD나 Gradient Descent로 학습을 용이하게 한다.
- 활성화함수를 사용할 때 이전에 많이 활용하던 Sigmoid나 tanh 같은 경우 값이 커지면 슬로프가 줄어들게 된다. 슬로프가 결국 기울기니까, 뉴런의 값이 많이 크면(0에서 벗어나면) Gradient Slope는 0에 가까워진다. 이 때 Vanishing Gradient 문제가 발생할 수 있는데, ReLU를 사용하면 해당 문제를 해소할 수 있음
- GPU Implementation (2 GPUs)
- Local Response Normalization(어떠한 입력 공간에서 Response가 많이 나오는 부분을 죽이는 것임. 최근엔 많이 사용되지 않음), Overlapping pooling
- Data Augmentation
- Dropout
지금보면 LRN을 제외하고는 당연하게 모두가 사용하는 테크닉들이 주요 아이디어로 사용되었다. 하지만 당시 2015년에는 당연하지 않았다. 일반적으로 가장 잘 되는 기준을 당시에 잡아준 것이라고 볼 수 있음.
VGGNet
- $3 * 3$ Convolution 필터를 사용하였다.
- 크기를 생각해봤을 때 필터의 크기가 커질수록 얻는 이점은 하나의 컨볼루션 필터를 찍었을 때 고려되는 인풋의 크기가 커진다는 것이다. (Receptive Field)
- $55$ 필터 하나와 $33$ 필터 두 개를 사용할 때 Receptive Field 차원에서는 똑같다. 하지만 파라미터의 개수는 400k vs. 294k 정도로 약 1.5배 차이가 난다. $3 * 3$ 레이어 두 개의 파라미터가 많을 것 같지만, 같은 리셉티브 필드를 사용한다는 전제로 봤을 때 필터의 크기가 작을수록 적은 파라미터를 가질 수 있다.
- $1*1$ FC레이어를 사용하였다.
- Dropout
- VGG16, VGG19 (레이어의 개수에 따라)
GoogLeNet
$1*1$ Convolution이 Dimension(차원) Reduction 효과가 있다. Convolution Feature Map이 witdh, height를 가질 때 special dimension이 아니라 Tensor의 Depth 방향으로 차원을 줄이는 것을 통해 파라미터 숫자를 줄일 수 있다.
AlexNet -> VGGNet 에서 배웠던 인사이트는 같은 리셉티브 필드에서는 필터 크기가 작은 것이 좋다는 것을 알아내었고, LeNet에서는 전체 파라미터를 어떻게 줄일 수 있을지를 알 수 있다.
- 네트워크 안에 네트워크가 있는 구조를 NIN(Network in network) 구조라고 한다.
- Inception Blocks
- $33$ Convolution을 하기 전에 $11 Conv$가 들어가는데 이것이 중요한 역할을 한다.
- Inception Block에서 여러 Response들을 Concat 하는 효과도 있지만 $1*1$ 이 들어감으로서 파라미터 수가 줄어들게 된다.
- $1*1$ Conv는 채널 방향으로 차원을 줄이게 된다.
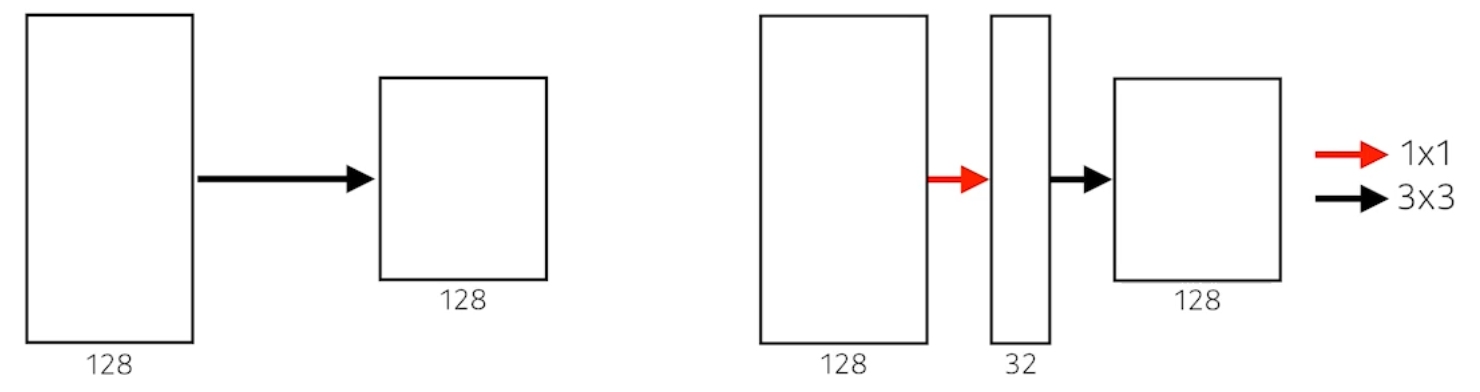
- 파라미터의 수는 $3 3 128 128 = 147,456$ vs. $1 1 128 32 \ X \ 3 3 32 * 128 = 40,960$ 이다.
- 입력과 출력의 사이즈는 똑같음, 즉 Receptive Field 차원에서 같은데 파라미터의 수가 약 1/3로 줄었다.
- $1*1$ Conv가 파라미터를 30% 가량 줄일 수 있다!
Which CNN Architecture has the least number of parameters?
- AlexNet (8-layers) = (60M)
- VGGNet (19-layers) = (110M)
- GoogLeNet (22-layers) = (4M)
ResNet
- General Performance: Train Error가 줄어듦에도 불구하고 Test Error가 Train Error와 나는 차이를 말함.
- Overffiting: Train Error가 줄어드는데 Test Error가 큰 현상.
- 하지만 Train Error가 더 작은데도 불구하고 Test Error가 더 크면, 학습이 되지 않는 것임.
- 기존에는 네트워크가 커지는데 학습이 더 잘 되지 않는 상황이 존재했음.
Key Ideas
- Add an identity map (skip connection) = Residual Connection
- 입력이 왔을 때 출력값이 나오는데, 이 때 입력 x 를 한 단짜리 Convolution에 더해주는 것임. 학습하고자 하는 것은 Residual 차이만 학습하는 것임. 차이만 학습하길 원하는 것이 Residual Connection을 사용한 ResNet임.
- $f(x) \rightarrow x + f(x)$
- 레지듀얼을 사용하지 않으면 네트워크가 많아도 학습이 잘 되지 않는다.
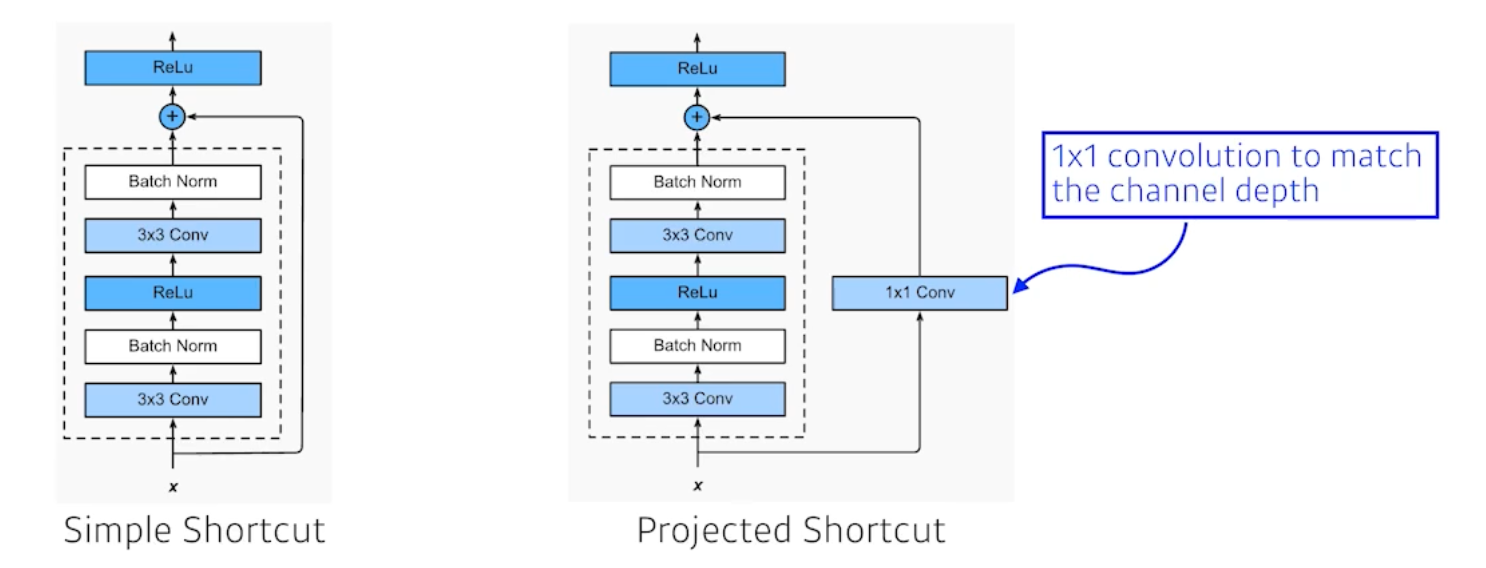
- 일반적으로 Simple Shortcut을 많이 사용함.
- Batch Norm 이 Convolution 뒤에 일어난다. 하지만 네트워크를 작성하다보면 Batch Norm 을 ReLU 뒤에 넣거나 안넣는 것이 결과가 좋을 때가 있다고 한다.
- Bottleneck architecture
- $3*3$ Conv를 하기 전에 Input 채널을 줄이는 구조이다.
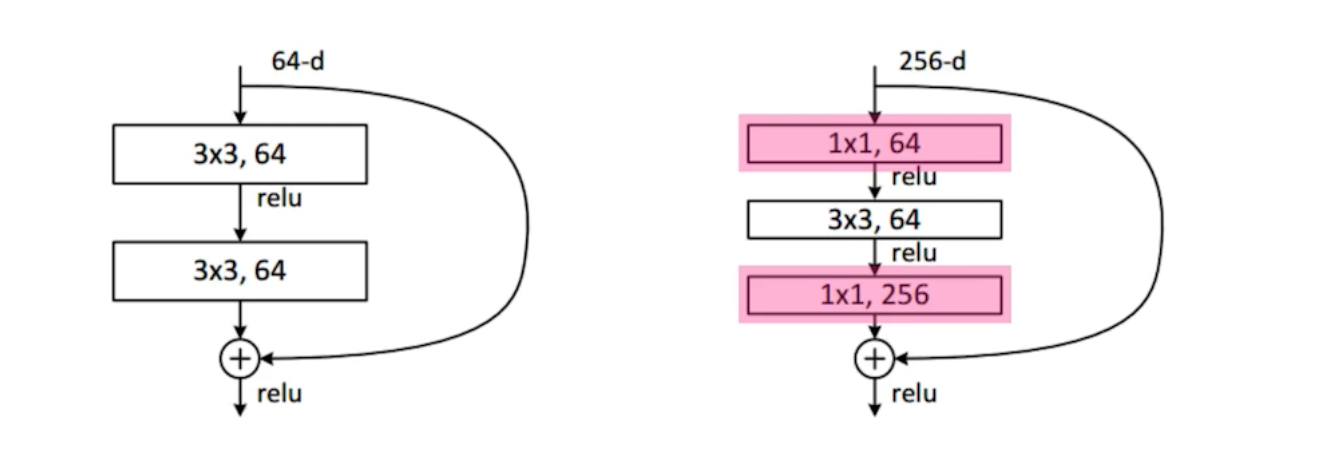
ResNet으로 갈 수록 성능은 증가하고 파라미터 사이즈는 줄어들게 된다.
핵심: $11$으로 채널을 줄이고 줄인 채널에서 $33 혹은 5*5$로 Receptive Fields를 맞춤으로써 파라미터를 줄여나가는 것이 핵심 전략이다.
DenseNet
ResNet은 결국 Convolution을 통해 나오는 값을 더해주는데, DenseNet의 아이디어는 더하지 말고 (왜냐면 성질이 섞이니까) Concat 하자는 것이다.
- DenseNet uses concatenation instead of addition
- Concat의 단점은 채널이 계속해서 커진다는 것인데, 이렇게 되면 Convolution Feature Map Channel도 같이 커지니까 파라미터도 커진다.
- 어떻게 채널을 줄이냐?
- $1*1$ Conv를 하면 됨.
- Transition Block
- $BatchNorm \rightarrow 11 Conv \rightarrow 22 AvgPooling$
Summary
- VGG: repeated $3*3$ blocks
- GoogLeNet: $1*1$ Convolution
- ResNet: skip-connection
- DenseNet: Concatenation
Convolution 소개
