Computer Vision Applications (Semantic Segmentation and Detection
Semantic Segmentation
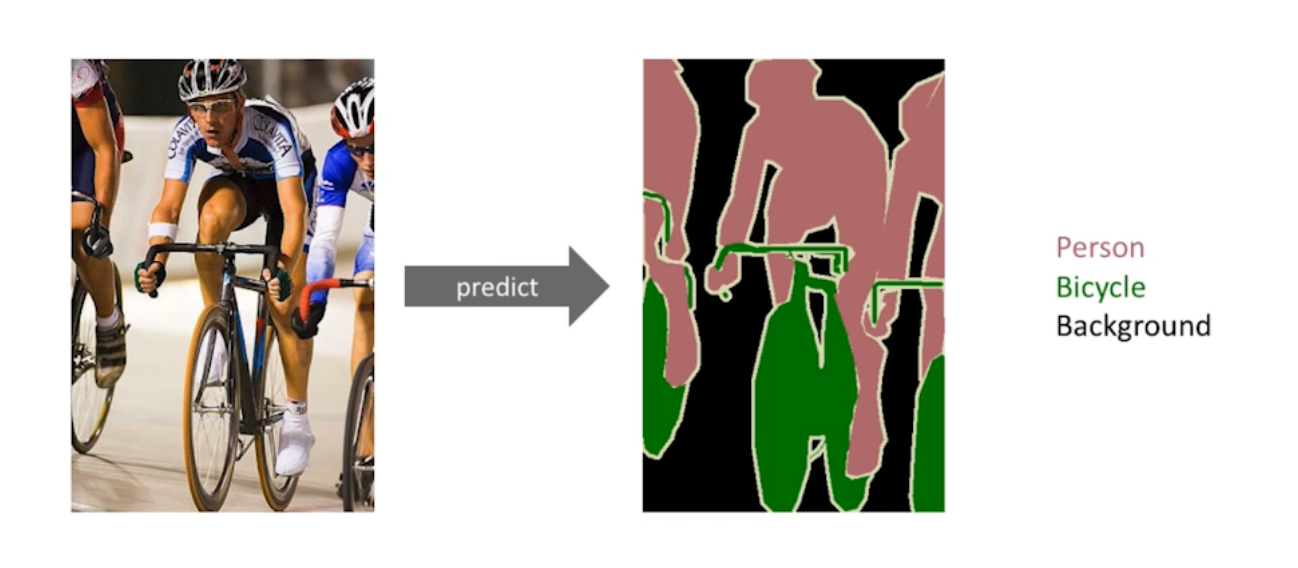
이미지 픽셀 별 분류 과제이다. Dense Classification, Perl Pixel 등으로 불리기도 한다.
Fully Convolutional Network
output이 1000개의 채널이라고 하면, Dense Layer를 없애고 Fully Convolutional Network 로 변경하려는 것임.
Fully Connected (Dense) Layer를 사용하는 것과 결과적으로 똑같음. 파라미터도 완전히 똑같음.
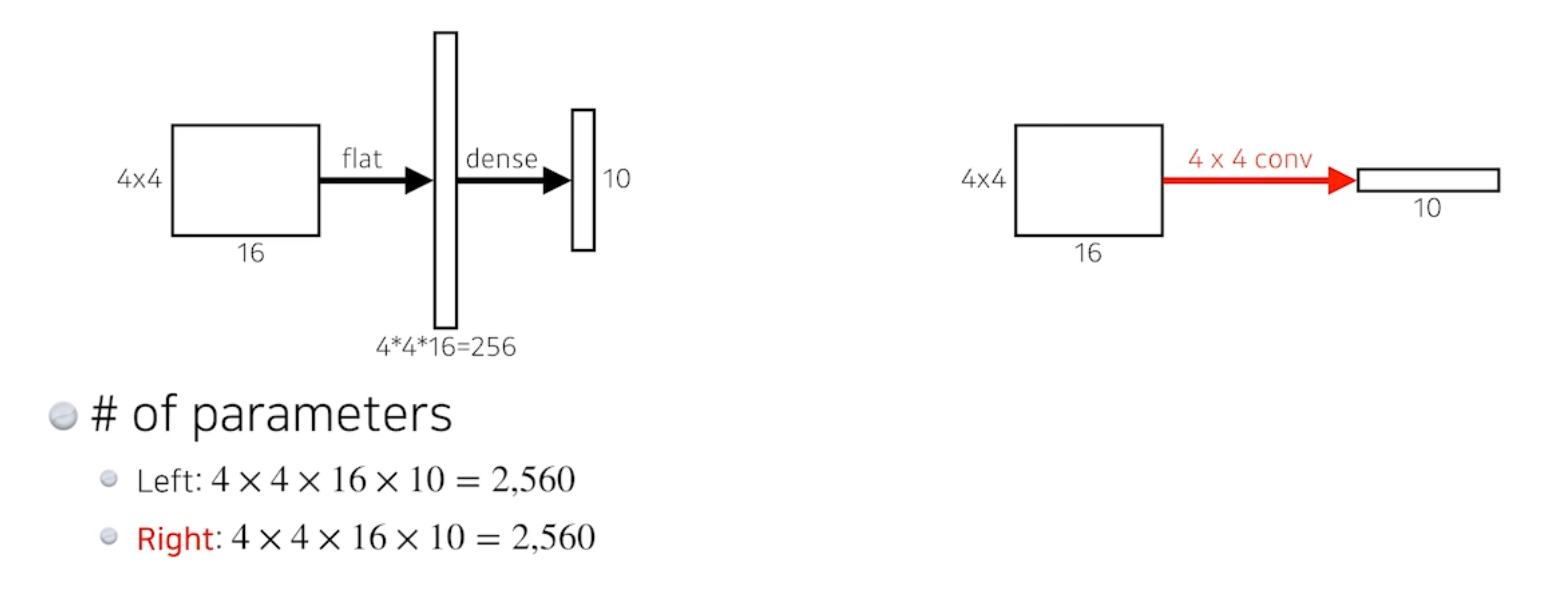
이러한 과정을 convolutionalization 이라고 한다.
- Transforming fully connected layers into convolution layers enables a classification net to output a heat map.
While FCN can run with inputs of any size, the output dimensions(special dimension) are typically reduced by subsampling. So we need a way to connect the coarse output to the dense pixels.
Deconvolution (conv transpose)
직관적으로 보았을 때 Convolution의 역 연산이다.
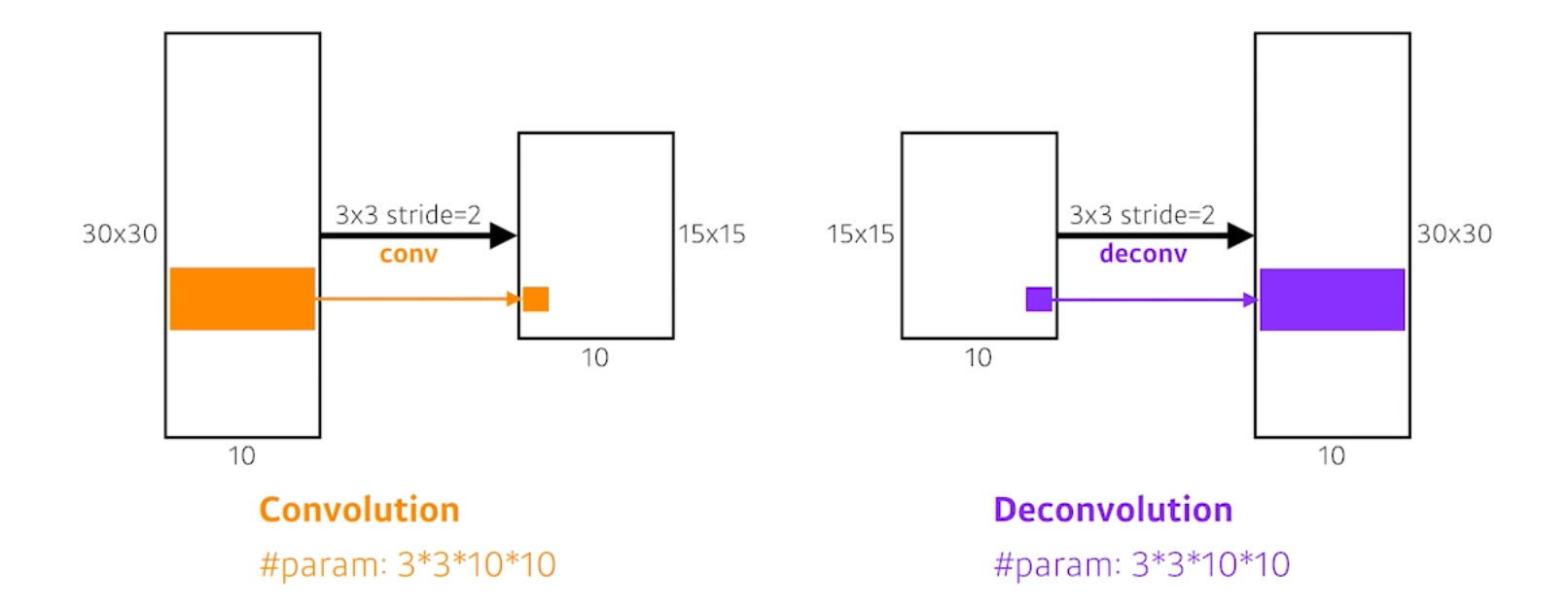
special dimension을 키워주는 역할을 하게 된다.
엄밀히 말하면 convolution의 역 연산은 존재할 수 없다. 원래의 값으로 완전히 복원할 수는 없기 때문이다. 하지만 이렇게 생각하면 좋은 이유는 네트워크 구조를 짤 때 파라미터 크기와 네트워크 입출력을 계산할 때 역으로 생각하면 편하기 때문이다.
Detection
Semantic Segmentation 이랑 비슷하지만, 퓨어픽셀을 이용한 히트맵을 찾는 것이 아니라 객체들의 bounding box를 찾는 과제로 만든 것이다.
- R-CNN
- R-CNN takes an input image,
- extracts around 2,000 region proposals (using Selective search),
- compute features for each proposal (using AlexNet),
- and then classifies with lenear SVMs.
- SPPNet
- RCNN의 가장 큰 문제는 이미지에서 2000개의 바운딩박스를 뽑았을 때, 2000개의 이미지 혹은 패치를 모두 CNN에 통과시켜야 한다. 즉 하나의 이미지를 처리하는데 CPU에서는 1분의 시간이 소요되었었다.
- 이미지 전체에 대한 컨볼루션 피쳐맵을 만들고, 뽑힌 바운딩박스 위치에 해당하는 컨볼루션 피쳐맵의 텐서만 뽑아온 것으로 CNN에 통과시킴으로써 훨씬 빨라지며, 한 번의 CNN으로 결과를 얻을 수 있다.
- Fast R-CNN
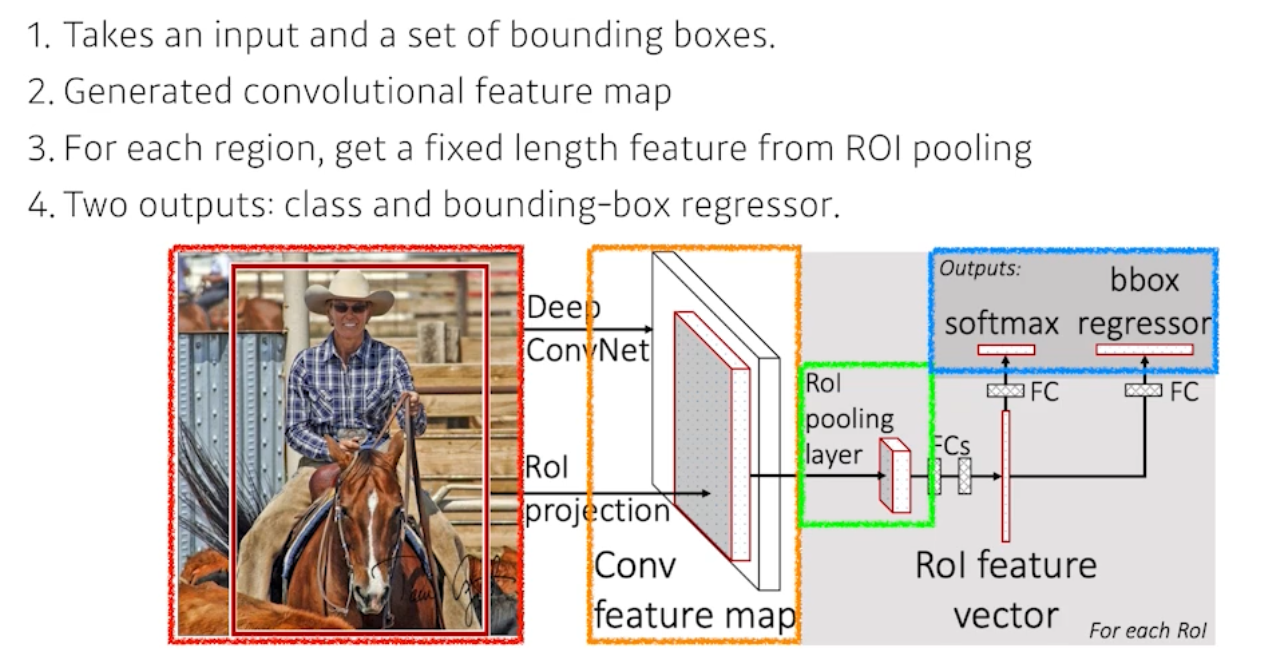
- 기본 컨셉은 SPPNet과 굉장히 유사하지만, 뒷단의 Neural Net(RoI)을 통해서 바운딩박스 리그레션과 분류를 진행했다.
- Faster R-CNN
- 이미지를 통해 바운딩박스를 뽑아내는 Region Proposal 역시 학습을 시키자는 것임.
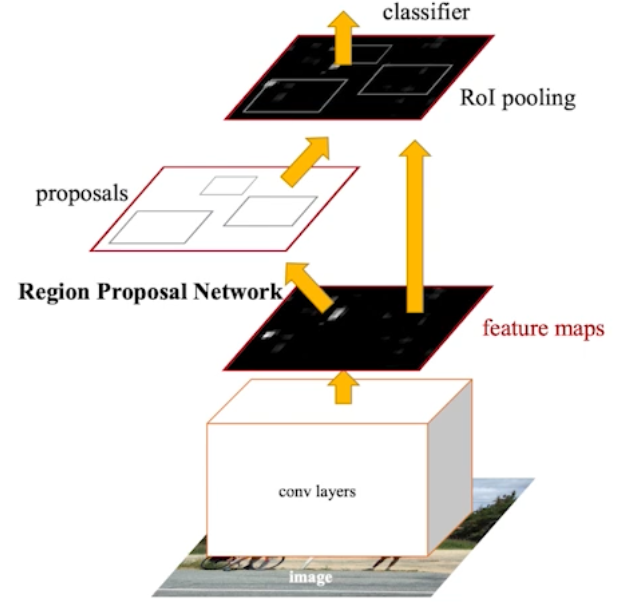
- Region Proposal Network
- 이미지가 있으면 이미지 속 특정 영역(패치)이 바운딩박스로서 의미가 있는지 없는지(즉 영역에 물체가 있는지)를 판단하는 것이다.
- anchor boxes가 필요한데, 이것은 미리 정해놓은 바운딩박스의 크기이다. 내가 이 영역에 어떤 크기의 물체가 있을 것 같다라는 예상을 전제로 만들어 놓은 것임.
- Fully Conv 레이어가 사용됨.
- YOLO
- extremely fast object detection algorithm
- It simultaneously predicts multiple bounding boxes and class probabilities.
- No explicit bounding box sampling (compared with Faster R-CNN)
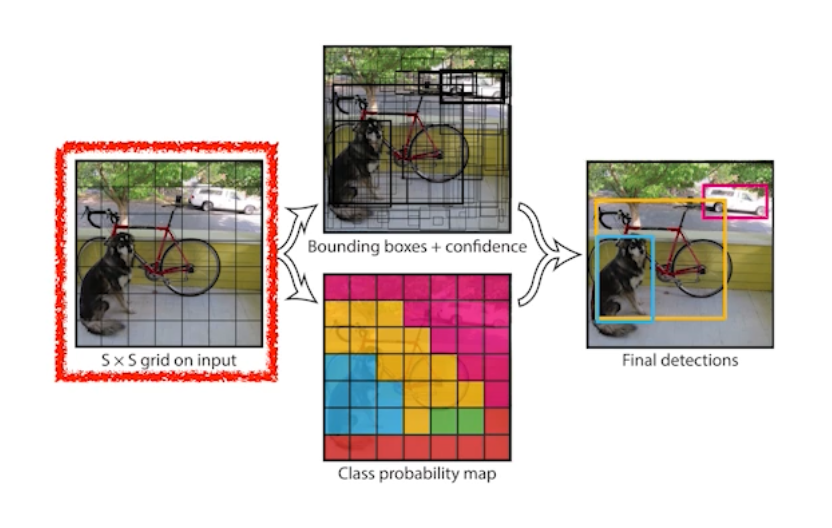
- 이미지 안에 찾고싶은 물체의 중앙이 그리드 안에 들어가면, 그 그리드 셋이 해당 물체의 바운딩 박스와 해당 물체가 무엇인지 같이 예측을 해야 한다.
- 이 때 B개의 바운딩 박스를 예측하게 된다. 이후 바운딩박스의 refinement(x/y/w/h)를 예측하고, 각각의 그리드셋이 속하는 중점의 오브젝트가 어떤 클래스인지 예측한다.
- 이 두 가지 정보를 취합하게 되면 박스와 박스가 어떤 클래스인지 예측할 수 있다.
Computer Vision Applications (Semantic Segmentation and Detection
https://l-yohai.github.io/Computer-Vision-Applications-Semantic-Segmentation-and-Detection/
