CV & NLP 선택가이드 - 업스테이지 서대원, 박선규
CV 도메인에 대하여 (박선규)
흔히 볼 수 있는 컴퓨터비전 태스크에 대한 사진
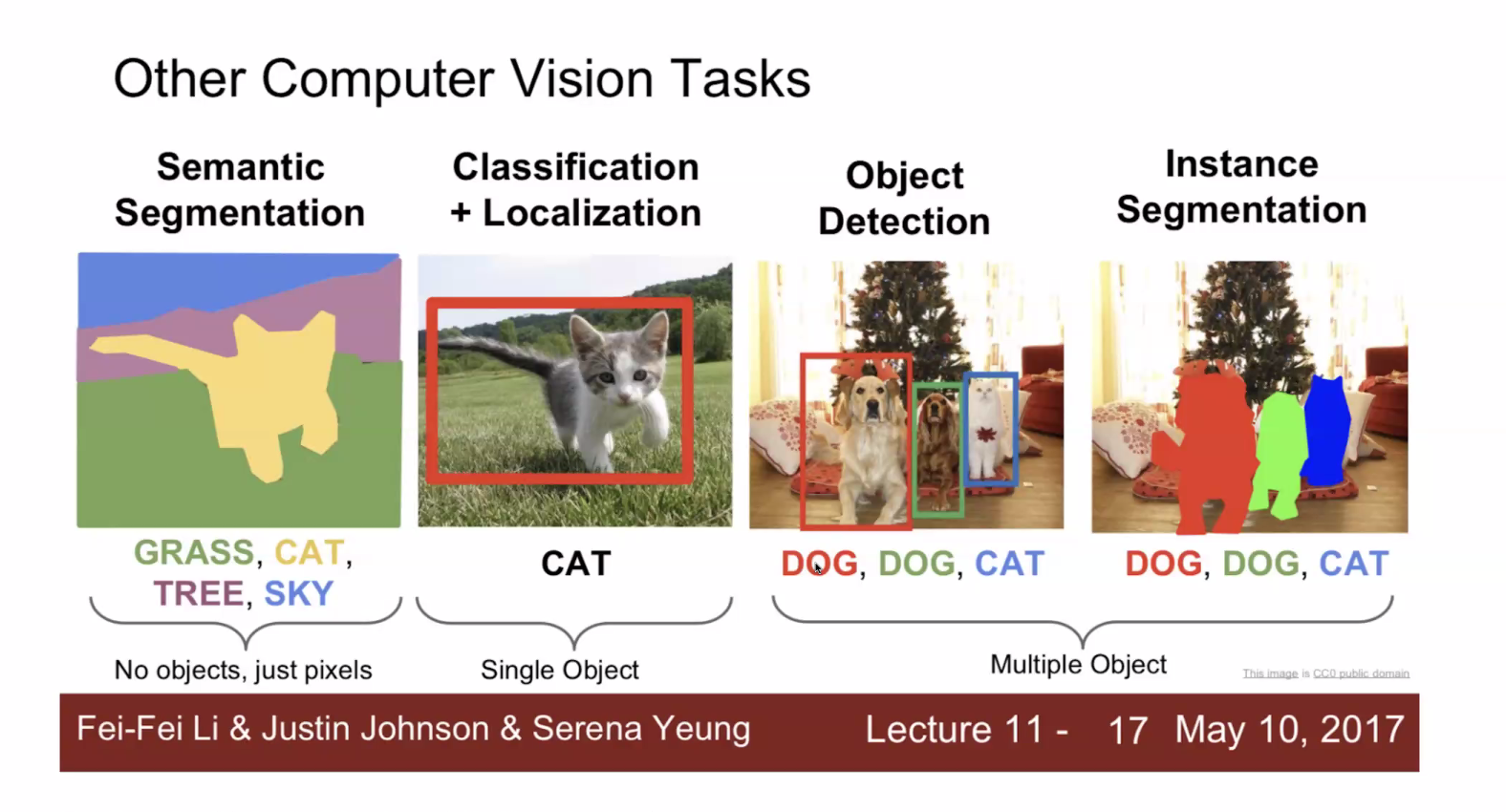
Taskonomy (CVPR 2018 Best Paper)

- 컴퓨터 비전에 관련된 26개의 태스크를 하나하나 정의하고, 한 태스크로의 모델을 학습시킨 후 전이학습에 대한 성능을 기준으로 두 태스크에 대한 관계(유사도)를 분석한 논문임.
- 태스크에 대한 연관관계보다는 태스크가 이렇게 많았구나..라는 인사이트를 얻게 됨.
- 이렇게 태스크가 많은데도, 학회를 가면 항상 새로운 것을 보게 됨. 연구분야가 굉장히 넓고 다양하다.
이미지에 관련된 것은 Convolution에 굉장한 의존성을 가지고 있다. 즉, Detection과 Segmentation 정도만 배우더라도 다른 컴퓨터비전 태스크를 접할 때 큰 어려움 없이 접할 수 있다.
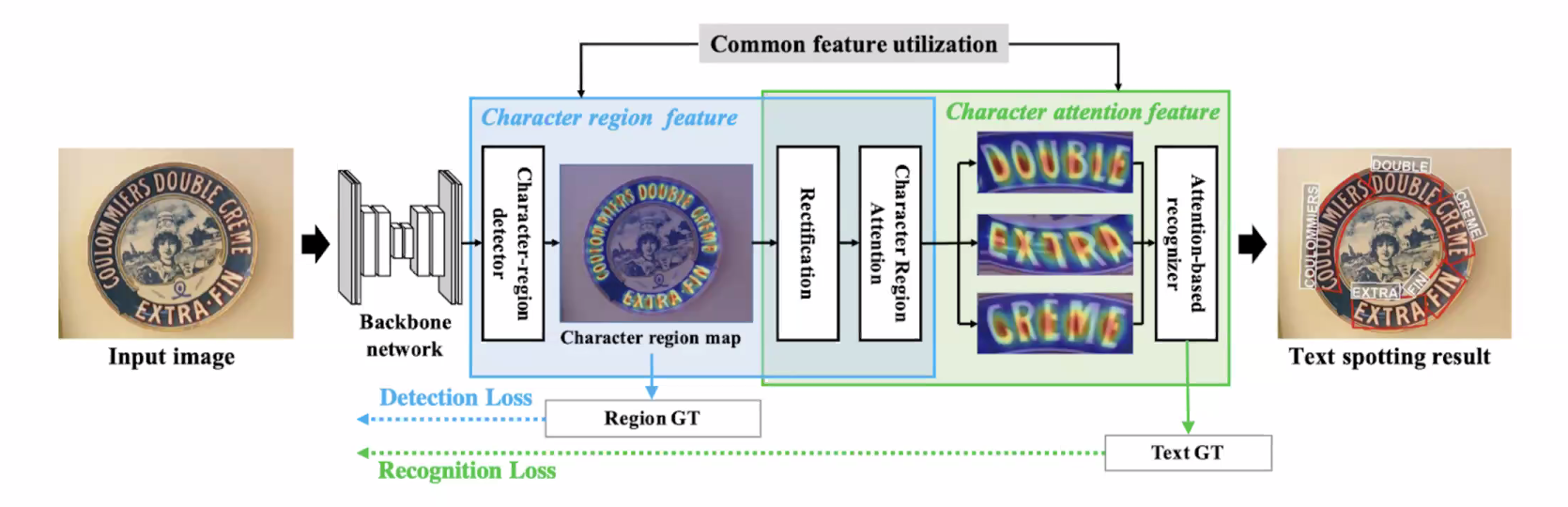
OCR
ViT
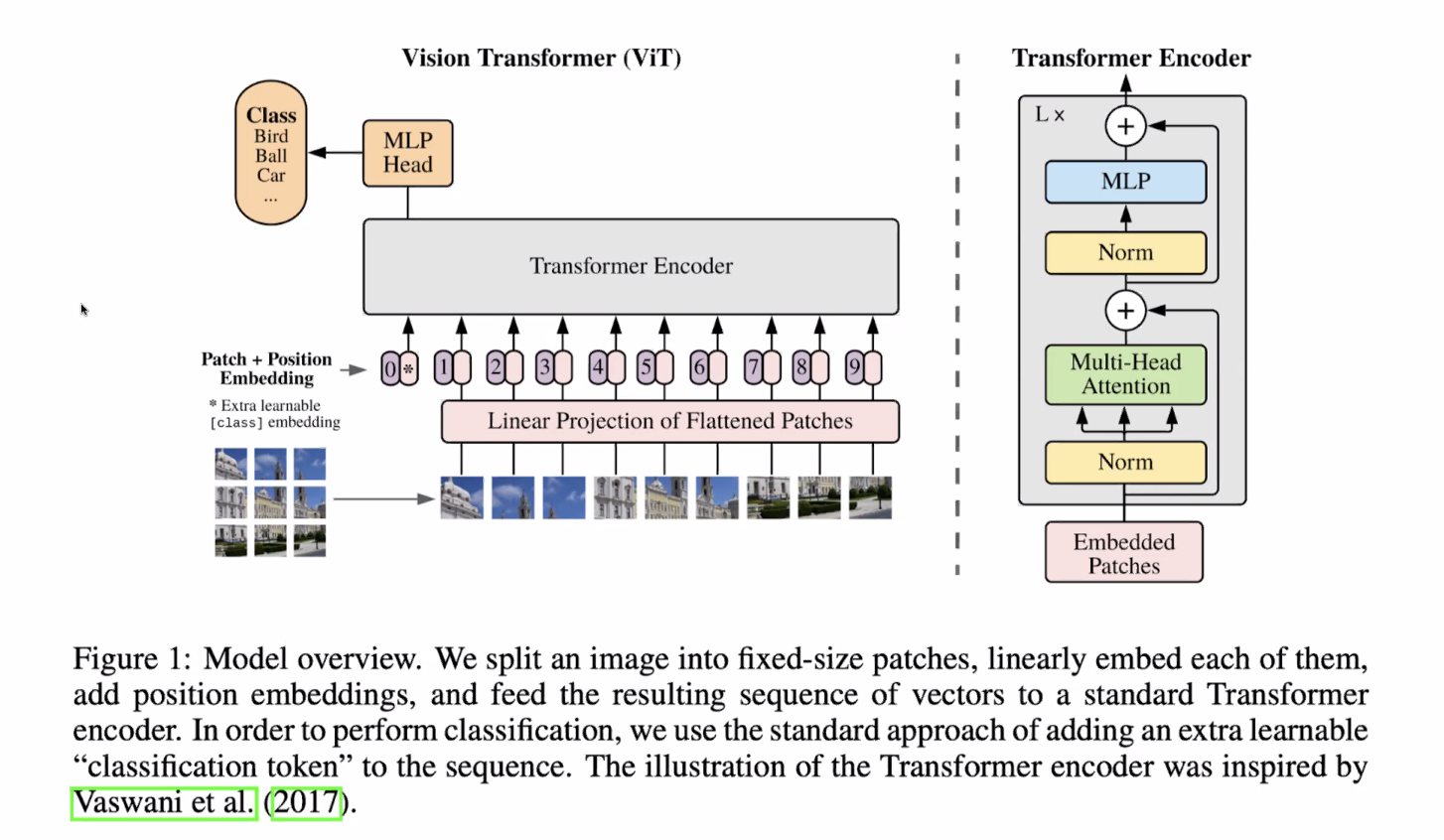
컴퓨터 비전의 대부분 태스크는 일반적으로 CNN을 기반으로 이루어지는데, 최근에는 Vision Transformer를 많이 사용한다. NLP에서의 Trnasformer는 데이터가 많아질 수록 성능이 높아지는데, 이미지 역시 데이터가 많아지니까 Vision Transformer의 퍼포먼스가 높아졌다. 그러나 아직은 CNN 기반 모델들이 서비스에 들어갈 확률이 높다.
Alias-Free GAN

ViT가 사람의 개입없이 데이터만으로 성능을 높여보자는 시도였다면, Alias-Free GAN은 몇 가지 아이디어만으로 원래의 GAN 문제를 해결하였다.
결론
컴퓨터비전이라고 하면 어떤 이미지나 시각정보를 다루는 방법론에 대한 연구이며, 시각 정보에 포함된 것들이 생각보다 매우 다양하다. 간단하게는 이미지부터 텍스트가 들어간 이미지 등, 생각보다 굉장히 다양한 서브태스크를 포함하는 굉장히 방대한 분야이며, 그 안에서 흥미가 있을 태스크를 찾아보는 재미가 있다. 또한 비전 관련된 커리큘럼을 선택하게 되면 Convolution 이라는 Operation과 CNN에 대해 굉장히 자세하게 배우게 될 것인데, 이것이 실 서비스에서 쓰이는 것들 중에는 이만큼 효율적인 것이 없기 때문에 부스트캠프에서 배우는 비전이란 지식이 굉장히 쓸모가 있을 것이다!
NLP 도메인에 대하여 (서대원)
NLP에 대한 정의
사람의 Document 를 해석하는 것에 밀접해있다. Document는 텍스트일 수도 있고 사람의 음성일 수도 있다. Document에서 의미를 뽑아내거나 혹은 단어 혹은 문장을 구별하거나 정보를 뽑아내는 모든 것을 포함한다.
NLU(understanding), NLG(generation)에 대한 분야가 있다.
Search

구글 검색창에는 전통적인 TF-IDF 가 이용되는 것이 아니라 언어모델이 들어가서 찾으려는 정보가 없어도 비슷한 정보들이 검색된다.
Voice Assistant
영화 HER에 나오는 인공비서를 만드는 것이 자연어처리 개발자들의 최종 낭만이지 않을까.
음성 인식을 먼저 하고 인식된 결과로 자연어처리를 하여 음성 합성까지 하는 태스크이다.
Translation
번역은 원래의 목적이 한 언어를 다른 언어로 변환하는 것인데, 해당 데이터가 다른 태스크를 학습하는 데 도움이 되기도 한다. Mono Lingual 태스크를 할 때 외국어 데이터로 Augmentation 할 수 있다.
Applications can be decomposed into LNP Tasks
다양한 NLP Task를 깊게 들어가다보면 결국에는 아래의 태스크들로 압축될 수 있다.

다양한 태스크를은 결국에 분류로 귀결이 된다. (단어 분류, 문장 분류, MRC나 QNA등도 결국에는 분류이다.) 숫자로 결과가 나오는 것이 아니라면 기본적으로 분류 태스크임.
Trend 1: Transfer Learning with Laaaaaaaaaarge Models
첫 번째 트렌드는 언어모델을 사용하는 것이고, 그 언어모델의 크기가 괴애애애애애앵장히 크다는 것이다. 대부분 언어모델들을 백본으로 삼아서 파인튜닝을 통해 학습을 하게 된다. GPT-2 가 나왔을 때만 해도 파라미터수 겁나 크다 생각했는데, GPT-3가 나왔을 때는 아.. 거대모델이 트렌드구나 생각할 수 있음.
Trend 2: Retrieval-based Model
Large Model의 경우 도서관의 모든책을 읽고 다 암기해! 와 똑같은 매커니즘이다. 하지만 Retrieval-based는 이런 정보들을 모두 하나의 모델에 넣는 것보다는 정보들을 각 모델에 나누고 책을 찾아서 답을 찾는 것처럼, Retrieval 된 Document 에서 정답을 찾는 것처럼 동작된다. DPR 같은 것들을 예시로 들 수 있다.
Trend 3: Multimodality
Text-to-Image(DALL﹒E: Creating Images from Text, OpenAI), Image-to-Text(Image Captioning)
결국에는 진행을 하다보면 다양한 형식의 데이터들이 들어오고, 데이터들이 연관된 Task를 학습하게 된다. 따라서 보통 사진/음성 등과 텍스트를 한 번에 학습시킬 상황이 발생할 수도 있음.
Voice Assistant를 학습시킬 때 음성데이터도 텍스트와 같이 학습함. 네~와 네?는 다르듯이. 따라서 NLU 중 음성텍스트 이해와 관련된 분야도 생기고 있다.
ML Engineers Implement ML Systems
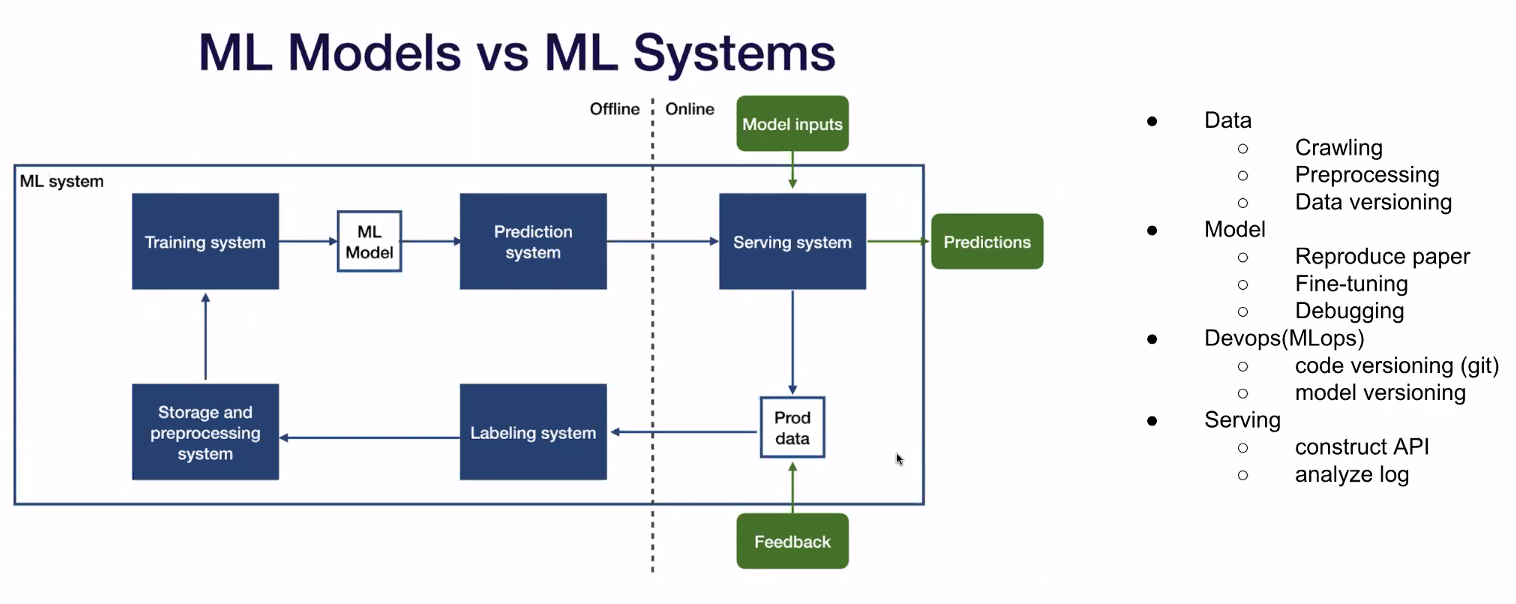
데이터를 크롤링하고 전처리 (데이터 버저닝 능력) 하며 모델 딴에서는 신경망 관련된 아키텍처의 이해가 필요하고, 이해를 바탕으로 새로운 논문이 나왔을 때 논문 수치를 재현하는 능력, 그리고 그 능력을 바탕으로 새로운 태스크에서 높은 성능을 내는 능력이 필요하다.
다음은 MLOps 처럼 코드와 모델을 관리하는 능력이 필요하며, 마지막으로 모델을 서빙하기 위한 API를 만들거나 실제 Production에 들어갔을 때 해당 모델의 Log를 분석하고 관리할 수 있는 능력이 필요함.
위에 것들은 차근차근 언젠간 다 알게 되기 때문에 주니어 레벨에서는 자료구조나 알고리즘의 기본기를 탄탄히 하고 ML Model에 대한 기본기를 탄탄히 하면 나중에는 위의 것들이 필요하다는 것만 인지하고 있으면, 나머지 것들은 나중에 자연스럽게 습득이 된다.
처음에는 NLP와 CV중 하나의 도메인을 깊게 파면서 추후에는 아 다른 데이터까지 다루어야 한다는 것을 인지하고 있을 것!
사전 질문 Q&A
Q: CV, NLP 분야 일을 하면서 가장 보람있었던 순간:
A: CV
OCR 분야로 인턴십을 하면서 무료 폰트들에서 글자를 뽑아내어 폰트 분류기를 만들어보자는 일을 했음. 해당 프로젝트라는 초라한(?) 계기로 홍콩으로 프로젝트를 갔다온 것이 뿌듯한 기억으로 남아있음.
A: NLP
본인은 문과였을 때부터 불평등 해소에 관심이 많았음. 정치를 통한 해소도 있겠지만 기술발전으로 불평등을 많이 해소할 수 있을 것이라 생각했음. 단적인 예로 학교를 다니다가 모 커피숍에서 나이가 있으신 분들은 다 줄을 서계시고 나이가 어린 사람들은 전부 사이렌 오더로 기다리고 있었음. 이것이 정보격차라고 생각하게 되었고, 이것을 어떻게 해소할 지 고민하면서 ‘디지털 푸어’들을 위하여 핸드폰에 음성명령으로 주문할 수 있게끔 하는 인터페이스가 있으면 누구나 다 잘 사용할 수 있겠구나 라는 생각이 들었음. 사이렌 오더도 그렇고 키오스크도 그렇고 정보 격차를 많이 일으키는 현상 중에 하나일텐데, NLP를 통해 해소할 수 있지 않을까라는 동기로 NLP에 관심이 있게 되었고, NLP를 하다보니까 Multi Modality를 해야겠구나라는 생각이 들면서 관심사가 확장되고 있다.
Q: 바이블같은 책, 혹은 재밌게 읽은 책 등.
A: CV
책은 잘 읽지 않는 편임..
A: NLP
책은 잘 모르겠는데, 요즘 NLP 모델들이 트랜스포머 구조로 대동단결하고 있기 때문에 Attention is all you need를 여러번 읽어보는 것이 좋은 것 같다. 반복해서 읽을수록 나의 이해가 부족했구나라는 생각이 많이 들게 된다. 그리고 또 한 번 읽고나면 까먹기 때문에.. Attention is all you need를 여러번 읽으면 도움이 많이 될 것이다.
Q: 최근에 가장 기억에 남는 논문이나 기술
A: CV
Multi Modality 논문에서 뉴런을 분석해보니까 글자를 읽는 영역을 따로 학습하지 않았는데 내부 뉴런에 반응하는 뉴런이 있더라! 하는 것. 그리고 Window Measurable 에서 사람이 말하는 ‘지능’에 대하여 고찰을 한 (프랑수아 쥴레) 논문을 인상깊게 보았음.
Q: 이미 경험해본 분야를 해야할 지 막 관심이 생기는 다른 분야를 선택해야 할 지 고민이 된다. (CV 프로젝트 해봤는데 NLP 해야되는가?)
A: NLP
CV나 NLP 모두 잡포지션이 매우 많고 유망하기 때문에 그냥 더 재밌는 분야 선택하는게 좋을 것 같다. 사실 또 재밌어하는 분야고 최종적으로 만들고 싶은 어플리케이션의 형태에 있는 분야여야지 본인이 열심히 하게 된다. 흥미가 있으면 이미 경험해본 정도를 금방 추월할 수 있기 때문에 좋아하는 분야 선택하는 것을 추천한다.
A: CV
본질적으로는 같은 답변인데, 본인이 생각했을 때 더 잘 할 수 있는 분야를 선택하는 것이 맞는 것 같다. 하지만 한 분야에서 깊이를 늘리는 것도 매우 좋은 접근이고, 그 분야에서 다양한 프로젝트를 해보는 것도 좋은 시도이지만, 본인의 경우 다양한 것을 해보고 싶어서 원래 공부하던 RL을 버리고 CV와 NLP를 공부했었다.
하지만 뭘 선택하든 현업에 가면 더 배워야하기 때문에 본인이 잘할 수 있는 것을 선택하는 게 취업시장에서 어떻게든 유리하게 작용할 것이다.
Q: 비전공자가 취업에 좀 더 쉽게 접근할 수 있는 분야라 하면 어느쪽을 골라야하는지, 또 업계 전반적인 구직현황은?
A: CV
좀 더 쉽게 접근할 수 있는 것이라고 하면 본인이 조금이라도 더 흥미를 느끼는 분야일 것이다.. 본인이 조금 더 쉽게 이해할 수 있어보이는 쪽이 좋아보임.
A: NLP
취업에 대해서는 Job Market이 굉장히 좋고 어떤 분야에서든 성과를 좀 내면 비전공자라도 둘 다 괜찮다. 본인의 경우 CV가 조금 더 어려웠던 이유는 삼각함수나 퓨리에 변환 등 이미지 처리 부분에서 심리적인 장벽이 있었기 때문에 조금 학습이 더뎌서 어렵게 느꼈었는데, 결국에는 CV든 NLP든 어려운 것은 다 해야된다.
AI와 ML에 많이 포커스를 두는 사람들이 많은데, Engineering에도 많은 포커스를 두는 것이 좋다. 즉 좋은 ‘개발자’가 되는 것이 중요함. AI가 조금 부족하더라도 코딩능력과 커뮤니케이션 능력이 좋다면 데려가려는 기업이 많을 것이라고 생각한다.
Q: CV와 NLP에 대하여 수강하게 될 때 각 분야에서 가장 중요하게 봐야할 부분은?
A: NLP
NLP에 대해서 설명을 드리면 커리큘럼을 봤을 때 상당히 좋은 커리큘럼이라는 생각이 들었다. 클루를 통하여 NLP의 태스크에 대하여 감을 잡고, 이러한 태스크를 기반으로 어떤 어플리케이션을 만들 수 있을까 고민하는 것이 중요하다. 가장 중요한 것은 언어모델에 대한 이해와 언어모델이 어떻게 학습이 되고 왜 잘되고 어떤 언어모델이 어떤 태스크에서 잘 되는지를 중점적으로 생각해보는 것이 좋음.
A: CV
CV에서는 사실 컴퓨터비전 내에서도 다양한 서브태스크가 많고 NLP나 음성에 대한 태스크도 있는데, 각 태스크마다 엔지니어링 요소들이 들어가는 것들이 있음. OCR을 했을 때 퍼포먼스를 위하여 Task Specific 보다는 네트워크 최적화 등의 테크닉이 필요할 수 있음. 그래서 이런 것들 위주로 생각해보는 게 좋고, 다른 태스크를 하게 되더라도 벽느끼지 않도록 공통적인 부분을 많이 챙기는 것이 좋음.
Q: NLP의 경우 각 언어마다 모델링을 할 때 많은 차이가 나는지?
A: NLP
차이가 날 수 있다. 한국어의 경우 형태소를 분석한 뒤 하는 것이 효율이 좋지만, 요즘 트렌드는 언어 의존도가 떨어지는 쪽이다. 그래서 요즘엔 동일한 토크나이징을 사용하는 등 의존도가 많이 사라졌다.
Q: 기존 인력 대비 차별점을 가지기 위해 어떠한 스킬을 계발하는 것이 좋을지.
A: CV
인력이 포화상태로 가고 있다는 생각이 잘 들지 않는다. 결국 해야할 것은 기본기가 잘 갖추는 것이다. 이 조건만 맞추기에도 면접은 매우 어려운 프로세스이고, 기본기가 충실한 사람이 잘 없다. 한가지 태스크를 바닥까지 파본 경험 혹은 매우 다양한 것들을 프로젝트로 접해봤다는 넓이도 차별점이 될 수 있다. 차별점도 매우 다양할 수 있다.
Q: 제조업관련 비전 기술을 성장하면 IT 기업에서 fit이 맞지 않을 수 있다는 두려움이 있음.
A: CV
특정 태스크를 가지고 프로젝트를 진행할 때 해당 태스크만을 위한 디테일들에 집중하게 되면 이러한 결과가 나올 수 있다. 다른 분야에서도 잘 쓰이는 테크닉인지 혹은 좀 다양한 분야에서도 유용하게 쓸 수 있는 기술들인지 생각하면서 개발하면 좋다.
Q: CS전공지식, 연구트렌드파악, 논문구현 및 서빙능력 위주로 공부하려는데 좋은 방향일지.
- A: 이것으로 가는게 맞다. 다 맞는 말임. 좋은 방향을 설정한 것 같고, 각 태스크 별로 뭘 해야하는지 세부적인 계획을 짜는게 더 좋을 것이다.
Q: 음성을 공부해보고 싶은데 접점이 맞는 NLP를 선택하고자 하는데, Engineer와 Researcher 중에 무엇이 어울릴지 판단하는데 도움이 될 방법은?
A: NLP
엔지니어와 연구원 중 무엇이 맞을지는 해보기 전에는 알 수 없다. 회사 사람들 중에도 둘 다 해본 사람들이 많다. 개인적으로는 둘 다 해보고 되는 곳을 가는게 좋지 않나.. 본인도 그랬음. 리서쳐 같은 경우 데이터가 고정되어 있고 데이터에서 성능을 어떻게 끌어올릴지 고민하는 경향이 큰 것 같고 모델링 관점의 실험을 통해 퍼포먼스를 높이는데, 엔지니어는 데이터의 형태가 고정되어 있지 않고 리서치 페이퍼를 참고하면서 모델들을 바닥에서부터 개발하기 보다는 베이스라인을 삼고 개발하고 서빙하는 것까지의 과정으로 진행되는 것 같다.
A: CV
둘 중에 선택하라 그러면 본인은 엔지니어를 선택했는데, 되게 심플하게 한 쪽은 논문을 읽고 쓰는 쪽, 다른 한쪽은 서비스를 만드는 쪽이라고 생각하고 판단했음. 그렇지만 완전히 분리되는 분야는 아닌 것 같다. 둘 중에 뭘 하든 둘 다 해야됨.
CV & NLP 선택가이드 - 업스테이지 서대원, 박선규
