AI Competition의 협업을 위한 플래닝가이드
🍡 떡볶이조 팀원들 🔥
| 김다영 | 김아경 | 문하겸 | 박지민 | 이요한 | 전준영 | 정민지 |
|---|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |

7명의 팀원이 2주동안 잠도 거의 안자가면서 올인했던 P Stage의 ‘마스크 착용 분류 대회’에 대한 플래닝 가이드입니다. 저희는 각자 실력도 다 다르고 협업문화도 잘 모르는 상태로 대회에 임하였습니다. 그러다 보니 뭘 해야할지 모르는 순간들도 너무 많았고, 여러 시행착오를 겪었기 때문에 다음 기수분들 혹은 인공지능 대회 프로세스 중 협업관리를 어떻게 하는 것이 좋을지 저희의 경험을 조금 나누어볼까 합니다.
당연히 처음엔 너무 막막했어요. 이게 잘 될까? 싶었던 대회였는데, 계속해서 시간과 에너지를 쏟으니 별로 경험이 없는 사람들 7명이서 38개 조 중 13등을 하게 되었습니다. 물론 순위권에 들었으면 좋았겠지만, 대회는 처음인 사람들끼리는 나름 성공적인 결과였다고 생각합니다. 이러한 저희 조의 이야기들이 어떤 형태로든 도움이 되고, 좋은 레퍼런스가 되기를 바랍니다.
🦆 대회 전략 수립 및 협업환경 구축
이번생에 협업은 처음이라..
- 협업을 위한 적절한 채널을 설정하고, 최소한의 Git에 익숙해지자.
- 대회의 목표를 수립하고, 핵심 가치를 팀원들과 공유하자.
🔥 대회 프로세스 소개 및 목표 설정
인공지능 대회는 간단하게 주어진 데이터셋으로 모델을 훈련시키고 성능만 올리면 되는 단순한 프로세스로 이루어져 있습니다. 하지만 세부적으로 보면 데이터 정제 및 전처리와 Labeling -> 실험을 위한 베이스라인 코드 작성 -> 모델링과 실험 -> 제출 의 프로세스를 가지고 있고, 보통 데이터셋 구축과 베이스라인 코드가 주어지는 경우가 많습니다.
이번 P Stage의 경우 지난 U Stage를 통한 학습이 끝나자마자 시작되었기 때문에 이러한 프로세스를 익히는 차원에서 데이터만 먼저 공개되고 베이스라인은 1주일이 지나서야 공개가 되는 형태였습니다. 따라서 빠른 실험을 위해서는 데이터셋 구축 작업과 베이스라인이 절실했고 그것을 하기 위해서는 팀원들과의 협업 방식에 대한 상의를 하고 대회 전략을 수립해야 했습니다.
지금 생각해보면 무모했으나 저희 조의 목표는 무조건 1등! 이었고 그에 따라 2주간의 대회 기간 중 1주차는 베이스라인코드 작성과 데이터 전처리에 집중하고, 2주차에는 성능향상을 위한 실험들을 전략으로 잡았습니다.
🤔 협업을 위한 채널 정하기
목표가 잡혔으니 이제는 협업을 어떻게 할 건지 결정해야 했습니다.
사전에 사용하던 채널로는 화상회의를 위한 줌, 공식적인 이야기를 위한 슬랙 채널, 그리고 코드관리를 위한 깃허브의 팀 Repo가 있었습니다. 하지만 이것만으로는 프로젝트 관리나 일정관리를 하기가 애매했어서, 새로운 채널을 만들 필요가 있었습니다. 해당 후보로는 Github Project의 대시보드, Jira, Notion 등이 있었는데 최종적으로는 Github Project를 사용하기로 결정했습니다. 칸반보드 기반의 Dashboard를 생성하면 TODO를 시각적으로 관리하기가 용이하고, Milestone이나 Label, Assignee 등 여러 장치들을 직관적으로 사용할 수 있기 때문입니다. 그리고 다른 템플릿 역시 다들 처음이지만, 사전학습 비용이 Github Project가 가장 적을 것 같았고, 채널이 다양해지면 다양할수록 팀원들의 혼란이 가중될 것 같다는 이유 또한 있었습니다.
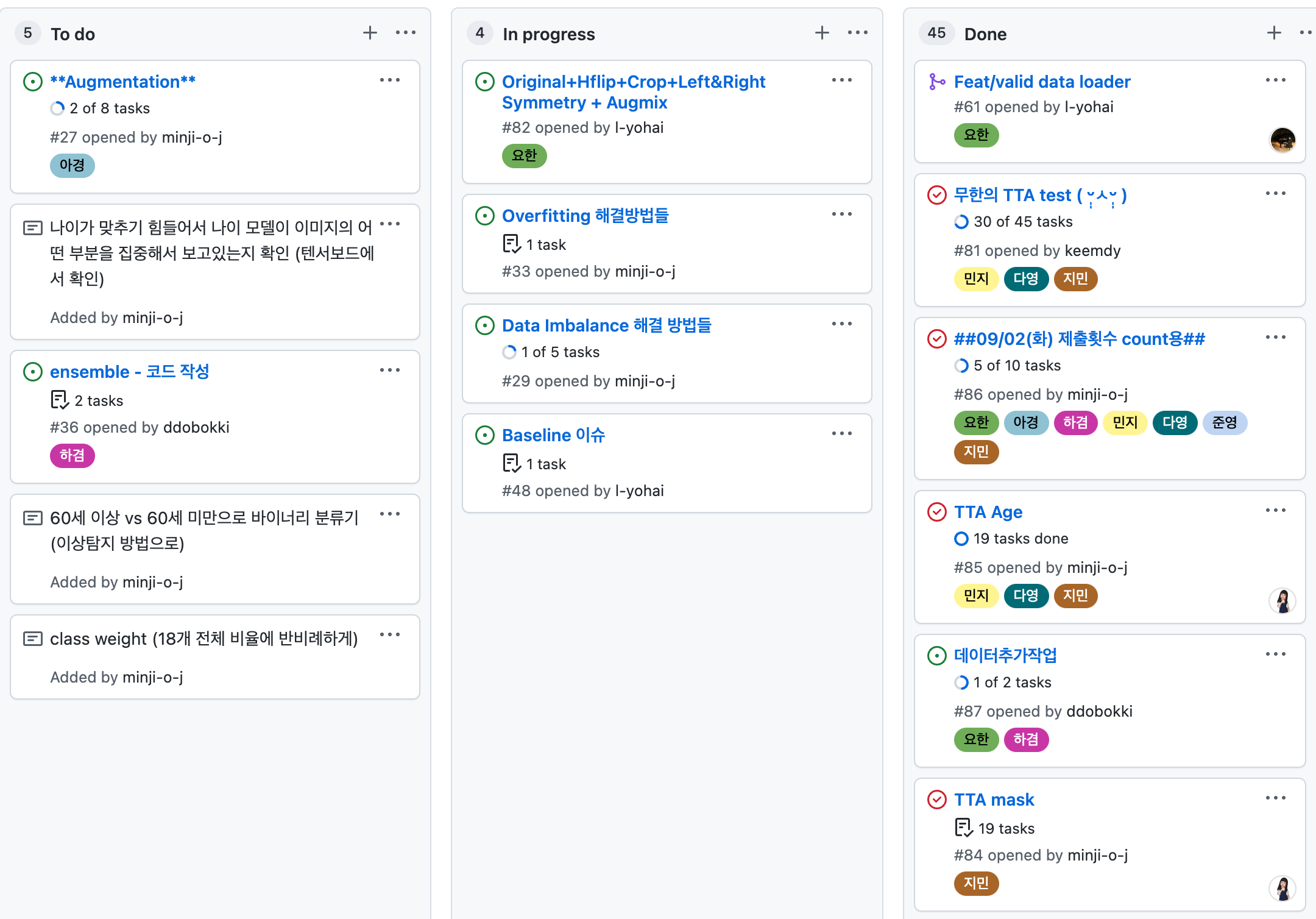
저희는 위의 사진처럼, Github Project의 Kanban Dashboard를 사용했고, 매일 아침 9시 30분마다 당일 작업할 TODO 리스트를 업데이트하는 식으로 진행했습니다. 그리고 각각의 이름을 가진 라벨을 만들어서 누가 해당 TODO를 작업중인지 표시하도록 했습니다.
이렇게 서로의 할일과 작업 결과를 공유할 수 있는 채널을 만들어놓고 어떻게 사용할지에 대한 Flow를 미리 정해놨다는 것 자체가 저희같은 협업 초보들에게는 큰 성과이자 시작점이었습니다. 채널마다 역할과 책임을 명확히하고, 해당 채널을 어떻게 사용할건지 팀원들과의 상의가 지속해서 이루어질수록 더욱 긴밀한 협업이 진행될 수 있음을 알게 되었습니다.
💻 코드관리와 Git (실패 🤮)
협업을 위한 채널 설정이 끝나고 마지막으로 코드관리를 어떻게 할 것인지 정해야했습니다. 1주차는 개인제출이 가능하다곤 하지만 결국에는 팀프로젝트이기 때문에 모두가 같은 베이스라인 코드를 가지고 중복된 실험을 하지 않고, 더 좋은 성능을 가진 코드가 나왔을 때 바로바로 버전업을 할 수 있도록 Git Flow를 따라서 협업을 진행하기로 결정했었습니다.
하지만 막상 대회 시작 후 베이스라인 코드가 너무 어렵고, 다른 할 것들이 많아서 정신이 없었으며 그리고 협업이 처음인 저희는 Git 자체가 너무나도 어려웠기 때문에 결국에는 Git Flow를 활용한 코드관리에 실패하였습니다.
하지만 Git을 활용하지 않으면서 점점 대회의 끝이 다가올수록 서로의 코드가 점점 달라졌습니다. 결국에는 어떤 한 명이 Best Score를 달성했을 때 그 방법을 공유받고 다른 사람들이 그 모델을 같은 방식으로 학습시켰을 때 다른 모두가 재현할 수 없다는 문제가 생겼습니다. 그래서 지금 생각으로는 다시 대회 초반부터 진행하게 된다면 무조건 Git을 활용해서 버전관리에 신경쓰면서 작업을 하고 싶습니다. 성능을 올린 결과를 계속해서 베이스라인을 삼고 해당 코드에서 다른 방법들을 실험하는 쪽으로요. 다른 동료분이 성능을 올렸다고 했을 때 “저거 어떻게 했지..”라는 좌절스러운 생각도 많이 했거든요.. ㅎㅎ; 그렇게 한두명씩 뒤쳐지게 되면 추후에는 더 많은 실험을 할 수 없게 돼요.
또한 대회에서는 성능 개선이 우선시 되기 때문에 시간을 오래 투자해야하는 Git flow까지는 아니더라도 간단한 flow를 사전에 정하는 것이 좋다고 생각합니다. 실험하기도 바쁜데 커밋 메세지 신경쓰고 PR 템플릿 찾아보고 있으면 빡치잖아요. 🤮
❤️🔥 핵심가치를 공유했다면 어땠을까?
협업에 있어서 가장 중요한 것 중 하나는 핵심 가치를 공유하는 것입니다. 많은 실험이 이루어지고 코드 규모가 커질수록 정말 정신없어지는 상태에서 수많은 의사결정을 해야합니다. 그러면 자연스럽게 의사결정 비용이 높아질 수 밖에 없고, 논의를 위한 시간이 길어지면 길어질수록 피로도는 높아지고, 일관되지 않은 코드를 짜고, 공유해야 할 것을 공유하지 못하는 등 어떻게든 본래의 목적을 달성할 순 있어도 협력이란 관점에서 정말 좋지 않은 일이 일어날 수 있겠죠.
처음에 정했던 목적 달성을 위해 조금 귀찮았어도 여러 가치중에서 우선순위를 정했으면 어땠을까 하는 아쉬움이 남습니다. 사실 대회 끝물로 갈 수록 여러 의사결정이 필요할 때 결론을 짓지 못하고 흐지부지 끝나게 되는 등 첫 주 차때의 열정이 점점 사라지고 있었거든요. 감정과 시간의 소모를 줄이는 일, 그것을 해결하려고 하지 않았던 것이 아쉬움으로 남는 것 같습니다.
구성원의 만족, 빠른 실험, 가독성, 일관성, 단순성, 통제가능성, 학습가능성, 안정성 등 협업에 필요한 가치들을 리스트업하고 그것들의 우선순위를 매겼으면 더욱 행복한 협업이 되었을 수도 있겠다는 생각이 듭니다.
🔎 EDA와 Custom Dataset 구축
데이터, 그게 뭔데?
EDA의 중요성을 잊지 말고, 다양한 실험을 위해 Dataset을 다양하게 구성해보자.
🌄 EDA와 데이터 정제
대회를 시작했다면 가장 먼저 해야할 중요한 일을 하나만 꼽으라고 한다면 그것은 바로 무조건 데이터의 형태를 파악하는 것입니다. 데이터의 분포는 어떻게 되는지, 데이터에 노이즈는 없는지, 잘못 Labeling 된 데이터는 없는지 등을 판단하고, 그렇게 판단한 결과를 토대로 데이터를 정제해야 원활한 학습이 이루어질 수 있기 때문입니다.
저희는 데이터를 지속적으로 관찰하고 분석하는 다양한 전략을 구상하였습니다.
1. 라벨 별 데이터가 어떻게 분포되어있는지 판단하자.
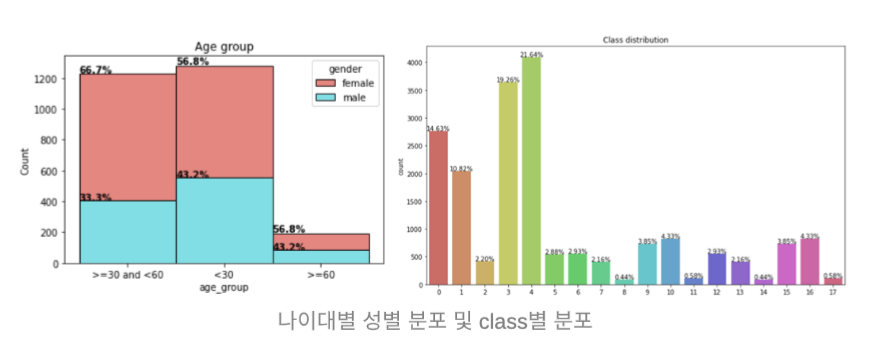
저희가 EDA 과정에서 가장 중요하게 생각한 것은 데이터가 Imbalancing 하지 않은지 확인하는 것이었습니다. 어느 한 쪽으로 데이터가 쏠려있으면 모델은 데이터가 적은 라벨을 쉽게 맞추지 못할 것이기 때문입니다.
2. Evaluation Dataset의 분포는 어떻게 되어있는지 확인하자.
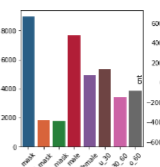
대회 1주차에는 하루에 개인별 10회씩 제출이 가능했습니다. 저희는 대회 초반엔 분명히 제출을 하지 못할 것이라 예상하고, 제출할 때 0부터 17까지 모든 라벨로만 Submission을 구성하여 제출했습니다. 이렇게 각 라벨별로 제출해보고 얻은 Accuracy 정보를 토대로 Evaluation 셋에 대한 정답 분포를 시각화할 수 있었습니다.
해당 방법은 이번 대회가 서버에 코드를 올려서 실행시키는 방식이 아닌, Eval Dataset을 주고 정답지만 제출하라는 방식의 대회였기 때문에 가능한 것이었습니다. 아래에서 또 이야기하겠지만, 이번 대회의 데이터셋으로는 과적합이 너무 쉽게 일어나고 Validation 데이터셋을 아무리 잘 나누어도 Validataion 관련 Score들을 신뢰할 수 없었습니다. 따라서 제출할 때 내가 도출한 정답이 어느정도의 Score일지 예상할 수가 없었습니다. 하지만 해당 방식으로 정답 분포를 알아낸 뒤 제출 전에 만든 정답지와 오차를 비교해보면 그 결과를 비슷하게 예측할 수 있었기 때문에 모델을 선택하고 제출할 정답을 고를 때 굉장히 좋은 판단 근거가 되었습니다.
3. 모든 데이터를 찍어보자.
제공받은 데이터는 사람마다 7장의 사진이 있고, 총 2700명의 사람이 있었습니다. 그렇게 총 18900개의 학습 데이터가 있었는데 저희는 팀원들끼리 분량을 나누어 위와 같이 모든 데이터를 확인하였습니다. 이 때 Labeling이 잘못된 것은 없는지, 데이터는 어떻게 생겼는지, 학습 중에 노이즈가 있을만한 요소들이 있는지 확인했습니다. 이 과정에서 남<->녀가 뒤바뀌거나 마스크를 착용하지 않았는데 마스크를 착용하고 있다고 파일명이 되어있는 데이터들을 탐지할 수 있었습니다. 또한 안경을 썼거나, 마스크를 눈에다 착용하는 등 학습에 방해가 될 수 있다거나 기이한 데이터들을 확인했습니다. 이렇게 모든 데이터를 확인하면서 학습 전략을 어떻게 취하거나 데이터 정제는 어떻게 하는 것이 좋을지 등 여러 실험 아이디어들을 얻을 수 있었습니다.
이와 더불어 실제 학습을 거쳐 모델을 생성한 뒤에 진행한 시각화로는 Confusion Matrix와 Wandb, Tensorboard 활용 등이 있는데 이것은 아래에서 이어서 말씀드리겠습니다.
🔧 Custom Dataset 구축하기
데이터를 확인했으니 Dataset을 구축하는 일을 진행해야 했습니다. 거창한 것이 아니라 데이터가 있는 경로의 폴더구조라던지, 이미지 파일의 확장자 등을 판단하고 데이터를 쉽게 불러올 수 있도록 csv파일을 만드는 것까지로 결정했습니다.
이 때 중요하게 생각했던 요소들은 Labeling을 어떻게 해야 할 지와 Validation 데이터셋을 만들어야 할 지에 대한 것이었습니다. 해당 내용을 가지고 많은 상의를 했으며 결론적으로는
- 통합라벨, Mask 착용여부, 성별, 나이를 포함하여 4개의 라벨을 갖도록 하자.
- 사람을 기준으로 Stratify 하게 나누어서 10%, 15%, 20% 비율로 split된 Validation Dataset을 만들자.
위와 같은 결과를 얻게 되었습니다.
저희가 분류해야 하는 라벨 개수는 총 18개입니다. 단일 모델로 18개의 라벨을 분류하라고 하면 성능이 굉장히 안좋게 나올 가능성이 크죠. 따라서 저희는 Mask 착용여부와 성별, 나이를 각각 분류하는 세 개의 모델을 학습시킨다음에 결과를 합치자는 쪽으로 전략이 기울었고, 그에따라 통합라벨을 포함한 세 개의 라벨을 추가한 csv 파일을 만들게 되었습니다.
그리고 Validation Dataset의 경우 동료 캠퍼분이신 서광채님의 토론글을 참고하여 사람을 기준으로 Stratify 한 데이터셋을 구축하였습니다. 빠르게 베이스라인을 만들고 먼저 실험을 진행하셨던 분들의 이야기를 들어보니 과적합 이슈와 Validation Score를 신뢰할 수 없다는 이야기를 듣게 되었습니다. 그렇기 때문에 Validation에는 처음보는 사람들이 들어갈 수 있도록 데이터셋을 분리하는 것이 좋겠다고 판단했으며 추후에 최종 제출을 할 때에도 판단의 도움이 될 것이라고 생각했습니다.
하지만 생각해볼 것은 어떤 특정 라벨에 대해서는 데이터가 굉장히 적게 분포되어 있는데, 적게 분포된 데이터가 Validation Set에 포함되어 있을 가능성에 대한 것입니다. 실제로 위의 방법을 사용했을 때 Validation Score는 조금이나마 신뢰할 수 있게 되었지만, 가뜩이나 적은 데이터가 학습에 사용되지 않았고, 대회가 끝나고 나서야 알게 되었습니다. 그것을 사전에 파악하지 못한 것이 조금의 성능향상을 방해했다고 생각합니다.
즉, Dataset 을 어떻게 구축하냐도 성능에 많은 영향을 미치기 때문에, 사전에 많은 상의를 통해서 여러 데이터셋을 구축하고 이후에는 많은 실험을 통해 택1을 하는 것이 가장 좋은 전략인 것 같습니다.
🎮 Baseline 구축과 적용
이 코드 어떻게 실행시키나요?
- 팀원들의 실력을 고려하여 베이스라인으로 삼을 템플릿 혹은 코드를 사전에 정해보자.
- 각자의 환경을 고려하여 베이스라인을 작성하자. (데이터 경로나 패키지 버전 등을 꼭 신경쓸 것!)
저희는 U Stage에서 배웠던 pytorch-template 을 이용하여 베이스라인 코드를 작성해보기로 사전에 협의를 했습니다. 왜냐하면 모듈화가 너무 잘 되어있고, 좋은 코드로 실험을 해야 좋은 모델이 나올것이라는 나름의 기대감이 있었기 때문입니다. (ㅎㅎ;)
하지만 결과적으로 성공이라고만은 말할 수 없을 것 같은데요, 왜냐하면 깃으로만도 머리아파 죽겠는데 여기에 어려운 코드까지 써야한다?? 네. 베이스라인 코드를 작성하고 이해하는데 너무 많은 시간이 걸렸습니다. 대회 기준 4일차에 베이스라인 코드가 완성되었고, 다음날에는 기존에 제공하기로 되어있던 베이스라인 코드가 공개되는 날이었어요. 그리고 해당 코드를 환경이 모두 다른 상황에서 팀원들이 일괄적으로 적용하는 것에도 많은 시간이 들었습니다.
빠르게 베이스라인을 작성하고 빠르게 실험을 이것저것 해보자는 계획을 실천하지 못한것에 꽤 아쉬움이 남네요. 그리고 지금 생각해보면 데드라인이 존재하는 대회의 경우에는 파이토치 템플릿처럼 유지보수와 기능 추가에 많은 비용이 드는 코드가 적절한지 잘 모르겠습니다. 차라리 주피터노트북에서 실행 가능한 코드들로 파이썬 스크립트를 만들었으면 어땠을까 하는 생각이 많이 들어요.
그렇다면, 지금부터 저희가 어떻게 베이스라인을 작성했고 파이토치 템플릿에 익숙해졌는지 말씀드려보겠습니다.
🥷 닌자 프로젝트
모던 자바스크립트 튜토리얼에는 Ninza Code 에 대한 이야기가 있습니다. 닌자라고 불리던 전설 속 개발자들이 사용했던 코드에 대한 이야긴데요. 코드는 짧게, 변수명과 함수명은 한글자만, 약어를 쓰고 동의어쓰고 최대한 헷갈리게 형용사도 많이쓰고 외부변수를 덮어쓰는 굉장히 멋있는(?) 방법의 코드 이야기에요. 개발자라면 분명 지양해야 하는 습관들이지만 파이토치 템플릿을 쓰기로 결정한 이상, 전설속의 닌자처럼 코드를 한 번 망쳐보자는 취지에서 Fashion-MNIST를 파이토치 템플릿으로 Fine Tuning 해보자! 라는 과제를 저희끼리 수행했어요. 그렇게 파이토치 템플릿을 한 번 망쳐보고 난 뒤에야 비로소 베이스라인을 작성하기 위한 최소한의 준비가 되었습니다.
✏️ Efficient Baseline
그렇게 닌자프로젝트를 진행한 이후에는 파이토치 템플릿으로 모든 코드를 작성할 수 있었습니다. 우선은 이전에 만들어두었던 csv 파일을 활용하여 CustomDataset과 CustomDataLoader를 우선적으로 만들고 config 파일에서 받아올 수 있는 인자들과 모듈들을 커스텀했습니다. 파이토치 템플릿 자체가 워낙 간단한 config 파일 수정만으로 모든 학습이 이루어질 수 있는 구조로 되어있다는 점을 인지하여 여러 가능성을 포괄한 코드를 만들기 위해 노력했어요.
베이스라인 코드를 작성할 때 아래의 것들을 원칙으로 삼아 구현했습니다.
- config 파일 수정만으로 분리해놓았던 각각의 라벨을 학습할 수 있게 하자.
- config 파일 수정만으로 pretrained 모델을 바꿀 수 있게 하자.
- config 파일 수정만으로 Augmentation의 값들을 변경할 수 있게 하자.
- config 파일 수정만으로 학습할 수 있는 데이터를 변경할 수 있게 하자.
- config 파일 수정만으로 여러 모델을 함께 학습할 수 있게 하자.
- config 파일 수정만으로 Evaluation 까지 동작할 수 있게 하자.
마침내 위의 원칙들을 적용한 베이스라인 코드를 만들게 되었고, 여러 기능이 추가된 탓에 복잡도는 올라갔고 시간이 오래 걸렸지만 좋은 코드를 입맛대로 변경하여 대회에 최적화된 코드를 만들 수 있었다는 것에 큰 즐거움을 얻었습니다.
하지만…
😂 코드 어떻게 실행해요? ㅜㅜ
가장 큰 문제가 발생했습니다. 파이토치 템플릿으로 멋스러운 베이스라인 코드를 만들었지만, 서로의 환경이 다름을 고려하지 못했고 그로인해 편하게 하려고 만들었던 몇몇 기능들이 다른 팀원분들의 환경에서 동작하지 않는 문제가 있었습니다. 특히 데이터는 용량문제로 깃에 올리지 못하기 때문에 저장된 경로가 모두 달랐는데, 경로 관련된 문제를 해결하는 것이 가장 힘들었던 것 같습니다. 또한 잘못된 Label을 수정하지 않은 팀원분의 경우 이미지를 불러올 수 없다거나, python이나 필요한 package들의 버전이 달라서 실행이 안된다거나 $PATH 와 같은 Alias를 수정하여 아예 필요한 패키지가 호출이 안된다거나 하는 기괴한 에러들이 수도없이 발생했습니다. 결국에는 어떻게든 해결하긴 했지만, 서로의 환경을 고려하여 패키지 버전을 Fix하는 등의 방식을 적용하지 못했다는 것에서 추가적인 비용이 많이 들었습니다.
이러한 이유로 1주차 때는 많은 실험을 못해봤고 이것이 더 성능을 올리지 못한 원인 중 하나가 될 것 같습니다. 다음부터는 Dot ENV 등을 활용한다거나 애초에 모두가 동일한 가상환경을 세팅하고 시작한다거나 하는 방식을 사용하는 것이 좋을 것 같아요. 정말 이 부분에서 많은 것을 배운 것 같습니다.
🥐 예상치 못한 파이토치 템플릿의 단점
어찌저찌 모두가 파이토치 템플릿을 사용하긴 했지만.. 예상치 못한 문제가 발생하기도 했습니다.
시간이 지날수록 여러가지 실험을 하고, 유용한 라이브러리를 사용해보는 등 여러 시도를 많이 하게 되는데요. 이 때 파이토치 템플릿으로 이루어진 코드들은 구조를 완전히 꿰고 있지 않으면 이 코드 어디에다가 붙여넣어야 되지..? 처럼 어디에 기능을 추가해야 될지 혼란스러워 지더라구요. 특히 대회에서는 빠른 실험을 통해 성능 향상이 보이면 해당 결과를 빠르게 공유하고 그 실험에 집중하는 것이 중요한데 빠르게 유용한 코드들을 손쉽게 적용할 수 없었어요.
또 하나, 파이토치 템플릿은 학습을 시킬 때 모델에 config 파일 역시 함께 저장을 시키는데 그렇기 때문에 모델을 불러올 때 config 파일이 없으면 load가 되지 않는다는 치명적인 단점이 존재해요. 이말은 즉슨, 이미 공유된 튜토리얼 코드라도 템플릿에 적용을 하거나 config 파일을 추가하는 수정비용이 들어간다는 뜻이겠죠.
고로 이런 부분들까지 생각을 해본다면, 원래 파이토치 템플릿에 익숙하지 않은 이상 다른 베이스를 찾아보는 게 더 효율적일 것 같다고 느끼게 되었습니다.
👨🔬 모델링과 실험
이렇게 하면 성능 오르는거 맞아?
서로가 무엇을 하고 있는지, 무엇을 해봤는지 모두가 자세하게 알고 있고,
어떤 것을 추가해봤을 때 오히려 성능이 떨어졌다는 것을 모두가 알고 있어야 하며,
성능이 올랐을 때 해당 성능을 재현할 수 있는 코드를 모두가 가지고 있어야 한다.
✂️ 정말 많은 실험을 시도함. 근데 실험 일지는?
간신히 베이스라인을 완성한 이후 저희는 정말 많은 실험을 해보았습니다.
Hard하게 Augmentation을 적용한 이미지를 데이터셋에 추가하기도 하고, albumentations 에 있는 모든 기능들을 정리하고 실험해 보았으며, ResNet, EfficientNet, RegNext, RegNet, MLP-Mixer, ViT 등 정말 많은 사전학습 모델을 사용해보고 Optimizer와 Loss를 계속 바꿔도 보고, CutMix, MixUp, AugMix와 같은 augmentation 기법들은 물론 TTA, Label Smoothing, Pseudo-Labeling 등 Data Imbalancing을 해결하는 방법들까지 사용해봤습니다.
시도해볼 수 있는 코드를 모두가 개인의 노력만으로 작성해서 실험해본 것도 너무 좋고, 프로그래밍 스킬이 늘어나고 파이토치 템플릿에도 익숙해지는 것은 정말 좋았으나, 결과적으론 위의 것들을 모두 시도해봤을 때 전체적인 성능 향상이 이루어지지 않았습니다.
그 이유는 체계적인 실험일지를 관리하지 않았던 것에서 찾을 수 있을 것 같습니다. 수많은 기법과 수많은 하이퍼파라미터들의 조합 중에서 최적을 찾는 것. 그것이 성능을 끌어올릴 수 있는 방법이지만 해당 실험들의 결과를 철저하게 기록하지 않고, 실험 순서를 정리하지 않았기 때문에 모두가 다른 조합들로 시도했을 텐데, 그 결과들이 모두 수집되지 않아서 체계적인 실험을 할 수가 없었습니다.
또한 실험을 통해서 성능이 오르는 것을 찾는 것도 중요하지만, 성능이 떨어지는 요인을 찾는 것도 그만큼 중요한데요. 왜냐하면 성능이 향상된 모델에서 해당 요인을 적용하지 않을 수 있기 때문입니다. 이렇듯 기록의 부재로 저희는 수많은 조합들을 매번 새롭게 찾아야만 했습니다. 다시 생각해보니 이것도 정말 아쉽습니다 ㅎㅎ.
🍟 공유에 진심이어야 한다.
또 한가지, 여러 이유가 있겠지만 그 중에서 ‘공유’에 관해서 이야기하고 싶어요.
저희는 Github Project 를 통해 서로의 TODO와 일정을 관리하고 있었지만, 시간이 지날 수록 점차 관리에 소홀해졌고 조금의 성능 향상이 있었을 때 그 방법을 올바르게 전파하지 못한 것 같습니다. 너무 빡센 일정에 다들 지친 문제도 있었지만, 베이스라인의 스노우볼이 여기까지 도달했다는 생각도 들었습니다. 사실 제가 안했다는게 가장 크지만요… (팀원분들 정말 죄송합니다.) 당연한 이야기겠지만 저는 이렇게 했더니 성능이 올랐어요~, 저 이거 실험해봤는데 별로였어요. 정도의 공유만으로는 팀 전체적으로 다양한 실험을 통해 성능을 이끌어 낼 수가 없었습니다.
지금 와서 돌이켜보면 왜 그랬지 싶은데, 저를 포함한 팀원 모두가 그만큼 순위에 집착했었고 다른 것을 신경쓸 여유가 없었던 것도 같아요. 하지만 정말 공유의 중요성을 뼈저리게 알 수 있었습니다.
그럼에도 종료 전날에 기적적으로 성능을 향상시켰으며 그때부터 조금이라도 성능을 올리기 위해 모두가 힘을 합쳐 앙상블과 TTA에 전념했고 종료 1초전까지 성능을 올릴 수 있었습니다.
🥉 최종 모델 개요
](https://user-images.githubusercontent.com/49181231/132098313-6f9e7f2e-376c-44c8-a57d-e56cffd10168.png)
최종적으로 사용한 모델은 아래 모델들이 결합되어 있는 구조입니다.
- 성별을 분류하는 regnety_006
- 마스크를 착용한 사람들로만 학습시킨 efficientnet_b1
- 마스크를 잘못 착용한 사람들로만 학습시킨 efficientnet_b1
- 마스크를 착용하지 않은 사람들로만 학습시킨 efficientnet_b1
- 마스크 착용 여부를 분류하는 regnety_006
처음 사전학습된 모델을 단일구성하여 18개의 라벨을 한 번에 분류하게 했을 때는 약 20%의 정확도와 0.18 정도의 f1 스코어를 기록했습니다. 성능을 향상시키기 위한 여러 방법을 고안하던 중, 3개의 Task로 나누어서 세 개의 모델이 각각 Gender, Age, Mask 착용여부를 분류하게 한 뒤 나온 결과를 조합하여 최종 라벨을 도출하게 하였을 때 약 70%의 정확도와 0.69 정도의 f1 스코어를 기록할 수 있었습니다.
위의 실험을 토대로 각각의 분류 모델을 활용하게 되었고, 여러 추가적인 실험을 바탕으로 Age 모델의 예측 결과가 좋지 않다는 것을 파악하게 되었습니다. 그래서 Age 모델도 (마스크를 착용한 사람으로만 학습한 모델, 마스크를 잘못 착용한 사람으로만 학습한 모델, 마스크를 착용하지 않은 사람으로만 학습한 모델) 로 분리하였고 결과적으로 나이 예측 성능을 향상시킬 수 있었습니다다.
🫂 앙상블

너 아이큐 150, 내 아이큐 150, 합치면 300!
하지만 이렇게 총 5개의 모델을 활용했을 때 ‘성별-나이’ 혹은 ‘마스크-성별’ 등 연관성이 존재할 수 있는 정보를 활용하지 못하고 독립적인 Feature로만 정답을 도출하게 되는데요. 따라서 의존적인 정보를 추가하고자 마스크 착용여부로 분리한 각각의 Age 모델들을 앙상블하였고 이후 Gender와 Mask 모델까지 통합하여 Multi Label Classification을 수행하게 하였습니다. 이렇게 0.75의 f1 스코어를 기록하였고 이후 최적의 TTA를 적용하고 제출 결과들을 Hard Voting 하여 최종적으로 0.766의 f1 스코어를 기록할 수 있었습니다.
💯 굿 프랙티스
결과적으로 옳았던 선택들
시각화와 로그는 무조건 옳다!
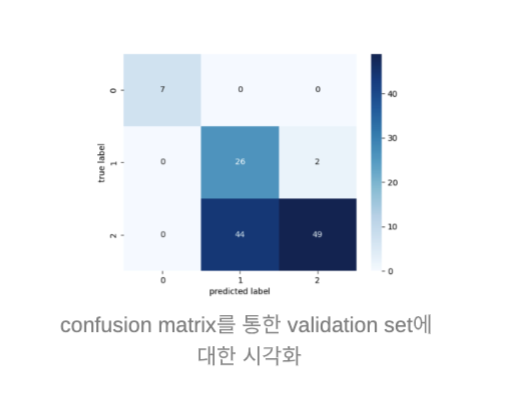
🎉 Tensorboard에 Confusion Matrix 시각화
🎉 Wandb 사용
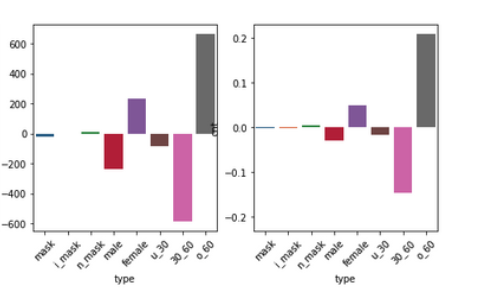
🎉 Evaluation에 대한 클래스별 오차 비율 시각화
🎉 TTA 실험일지 작성

지금 생각해도 저희가 잘 한 것은 바로 모든 것에 로그를 남겼고, 시각화 툴을 잘 이용했다는 것입니다. Wandb와 Tensorboard를 적극적으로 활용하였으며, 데이터 분석 단계에서 0~17로만 채워서 제출한 결과를 통해 Evaluation 데이터의 정답 분포를 알아냈고 저희가 제출할 정답과 클래스별 오차비율을 계산해냈습니다. 그 결과 제출 전에 나름 신뢰할 수 있는 근거들을 잘 만들어놓았다는 것이 미흡한 협업에도 좋은 결과를 이끌어낼 수 있었던 전략이라고 생각합니다.
너무나도 쉽게 과적합이 일어나는 이번 대회에서 최소한의 제출 모델 선택 전략은 필수적이며, 아무리 Validation 데이터셋을 유의미하게 나누었다고 해도 웬만하면 90% 이상의 정확도를 기록했기 때문에 이러한 시각화 자료들이 꽤 중요한 모델 선택의 지표로 작용할 수 있습니다.
또한 최종 모델에서 TTA를 적용할 때 augmentation 기법들에 대한 조합별로 스코어를 기록했으며 최적의 augmentation을 찾아냈다는 것이 성능향상에 유의미하게 작용하였습니다. 저희는 TTA를 적용했을 때 최대 0.746 -> 0.763 까지 0.017 정도의 f1 스코어 향상을 보았고, 이 부분만큼은 체계적인 실험이 이루어졌기에 많은 도움을 받을 수 있었습니다.
마지막으로
돌이켜봤을 때 잘한 것보다 아쉬운 것들이 더 많이 남는 대회였던 것 같습니다. 비록 대회 전에 세웠던 1등이라는 목표를 달성하진 못했지만, 그럼에도 이후엔 어떤 식으로 협업을 하는 것이 좋을지 고민해보고 배울 수 있었던 경험이었던 것 같습니다.
너무 좋은 팀원분들과 함께할 수 있어서 정말 좋았고, 이번 경험을 통해서 저를 비롯한 다른 분들도 이후 대회에서는 모두 원하는 목표 충분히 이루실 수 있을 것이라 생각합니다.
저희의 이야기가 조금이라도 도움이 되었길 바라면서 마치겠습니다.
긴 글 읽어주셔서 정말 감사합니다!
🤜 부록: 팀원들의 한마디
요한: 실험 일지와 코드를 체계적으로 관리하지 못한 것이 가장 아쉽습니다. 서버가 5킬을 당한게 좀 컸던 것 같아요. 그래도 너무 좋은 팀원들과 미흡하지만 재밌는 대회 함께 진행할 수 있어서 너무 좋았습니다!
지민: 모두 항상 열심히 하시는 모습이 자극이 되어서 같이 완주할 수 있었던 것 같습니다. 특히 요한님 베이스라인 부터 모르는 부분 질문까지 친절하게 답해주셔서 감사했습니다!!
하겸: 아쉬운 점 투성이지만 성장통이라고 생각합니다.
다영: 첫 대회라 곱씹을수록 아쉬운 점이 많지만 좋은 팀원들을 만나 끝맺음이 좋았습니다 ! 덕분에 많이 배웠고, 자극도 많이 받았습니다. 지속 가능한 성장을 위해 파이팅 !!
민지: 잘한점이 너무 많지만!! 지나고 보니 아쉬움 투성이인 것 같습니다. 특히 리더보드 스코어 향상을 목표로 하신다면 다른 팀원의 코드로 빠르게 업데이트하고, 실험을 잘 기록해두는 것이 중요하다고 느꼈습니다. 지식 뿐 아니라 협업 과정 측면에서 배운 점이 많은 대회였습니다!
아경: 멋있는 분들과 함께해서 좋았습니다. 되돌아보면 아쉬운 점도 많았지만 그만큼 배운 점도 많은 것 같습니다. 이번 대회를 시작으로 더 발전하길! 화이팅 🙂
준영: 처음하는 DL, 처음하는 Competition, 처음 써보는 pytorch. 모든 것이 어색했지만, 좋은 팀원과 함께 해서 영광이었습니다. 항상 열심히 하시는 모든 팀원분들께 많은 자극을 받았습니다. 감사했습니다.
✨빛예닮 멘토님✨: Boostcamp에서 스스로를 정말 잘 Boost시킨 팀이라고 생각합니다! 혼자 앞서가기보다 모두가 함께 가는 것을 택했고, 오늘보다 내일을 더 기대되게 했던 우리 15조! 부족한 멘토와 함께였지만 여러분들 덕분에 우리 조가 더 빛난 것 같아요! 언제나 응원합니다! 감사합니다!
AI Competition의 협업을 위한 플래닝가이드
https://l-yohai.github.io/AI-Competition-and-planning-guide/
