AI Bookathon 대상 후기
2021 SKKU AI x Bookathon 대상 후기
대회 및 팀원 소개
북📚이온앤온 팀원들
| 허은진 | 윤채원 | 김종현 | 곽진성 | 이요한 |
|---|---|---|---|---|
 |
 |
 |
 |
 |
본 글은 5명의 팀원이 무박2일동안 한숨도 안자가면서 열중했던 제 3회 AI x Bookathon 대회 후기이자 솔루션입니다.
제 3회 AI x Bookathon 은 성균관대학교와 MindsLab 이 협약하여 주최되었고, Naver Clova 의 후원으로 진행되었습니다. 약 60여개 팀이 참여했던 예선을 거쳐 총 15개의 팀이 본선에 참여하게 되었습니다. 본선에서는 16일 오후 3시부터 17일 오후 12시까지, 참여팀들은 21시간동안 2만자의 수필을 생성해야 했습니다.

21시간이라는 짧은 시간이었지만 주제 선정 과정부터 모델링, 생성과정에서 여러 문제를 해결하고 차별점을 두기 위해 많은 시도와 실험을 하였고, 결과적으로 1등을 하며 대상을 받을 수 있었습니다.
막연한 순간들이 매우 많았지만, 그럼에도 여러 시행착오를 겪고 극복하며 완성도 있는 작품을 만들어낸 저희의 이야기가 좋은 레퍼런스가 되길 바라면서 시작해 보겠습니다.
대회 전략
Linux 서버에 T4 한 개의 GPU를 제공받았으며, MindsLab 의 자산인 GPT-2 를 Wrapping 된 형태로 제공해주었습니다. 제공해준 모델을 통해 Fine-tuning 을 진행하는 과정은 팀 별 주어진 Linux 서버에서 Mindslab 서버에 학습 요청을 하면 학습 로그와 함께 모델의 Checkpoint 를 Response 해주는 형태였습니다. 그렇다보니 실제 Train 과정의 Customizing 이 불가하였고, 데이터 정도만 변경할 수 있는 구조였습니다.
때문에 저희는 Public 으로 공개된 사전학습 GPT 모델을 선정하여 Train 과정을 직접적으로 조절하고 튜닝할 수 있도록 전략을 수립하게 되었습니다. 구조 자체를 파악하기 어려운 모델을 사용하는 것보다는 Benchmark 가 공개되어있고, 저희에게 익숙한 코드를 사용하는 것이 자유도나 작업 효율면에서 효과적일 것이라고 생각했기 때문입니다.
따라서 대회 시작 이후부터는 빠른 실험을 위하여 Huggingface 의 transformers 라이브러리를 사용한 GPT 모델의 training 과 inference 과정의 baseline 코드를 작성하였고 baseline 이 완성된 이후엔 생성해낼 작품의 주제를 결정하고, 결정된 주제에 맞게 데이터 수집과 전처리, fine-tuning, generating 과정을 거쳐 최종 제출물을 산출하기로 하였습니다. 또한 평가항목중에 유사도 검사가 있었기 때문에 AI가 만들어낸 원작을 최대한 변형시키지 않는 쪽으로 수필을 만들어내고자 했습니다.
데이터 수집 및 전처리
데이터 수집
적절하고 좋은 필체의 수필을 생성하기 위해서 퀄리티 좋은 데이터가 많이 필요했습니다. 데이터를 수집할 때 여러 고려사항들이 있었습니다.

모델이 적절한 문장을 생성하기 위하여 어느정도 scale 의 데이터를 사용하거나 어느정도 step 을 학습시켜야 할 지 몰랐으며, 저희 과제와 알맞는 데이터는 어떻게 선별할 것인지, 또한 대회 규정에 맞는 데이터 저작권 문제도 해결해야 했습니다.
따라서 대회 규정에 맞는 데이터 수집 채널을 먼저 선정하고, 최대한 많은 양의 데이터를 수집한 뒤 그 후에 선별작업을 추가적으로 하기로 계획했습니다. 저희는 수필에 해당하는 글들이 많은 브런치의 ‘감성 에세이’ 탭에서 ‘산문’, ‘산문집’, ‘수필’, ‘힐링에세이’, ‘일상에세이’ 정도의 Tagging 이 되어있는 웹페이지에서 약 8시간 정도의 크롤링 작업을 진행했습니다. 또한 문학광장 사이트의 글틴(명예의전당), 신문사들의 신춘문예 당선작을 추가로 수집하게 되었습니다.



그렇게 약 160Mb 의 데이터를 수집할 수 있었습니다.
데이터 전처리

수집한 데이터에는 \n 과 같은 escape character 부터, 초성이 반복되는 ㅋㅋㅋㅋㅋ 혹은 광고 문구, bad character 들이 많이 포함되어 있었습니다. 이러한 noise 들은 KLUE: Korean Language Understanding Evaluation 논문에서도 유사하게 나타났던 문제였기 때문에 KLUE 에서 사용한 전처리 방법을 차용하여 사용하였습니다.
1 | def preprocessing(text): |
사용한 전처리 코드는 위와 같습니다. 해당 방식으로 Bad characters, Email, Special Character, image link, duplicated, punctuation 등에 대한 cleansing 작업을 진행할 수 있었습니다.
그렇게 전처리된 데이터의 예시는 아래와 같습니다.


하지만 막상 수집한 데이터를 EDA 해보니 2만자 분량의 글을 생성해야 하는데 2만자를 초과하는 글이 하나도 없었습니다. 때문에 하나의 모델이 2만자를 한 번에 생성하고자 하면 분명이 내용적으로 많은 문제를 일으킬 것으로 예상했습니다. 따라서 저희가 모은 데이터를 효율적으로 활용하면서 적절한 글을 생성하기 위한 방법을 고민하게 되었습니다.
주제 선정 및 Retrieval
한 대의 T4 GPU 에서 저희가 수집한 대량의 데이터를 학습시키고 하나의 주제가 관통하는 일관성있는 글을 쓰기엔 시간적으로, 그리고 하드웨어적으로 제약이 존재했습니다.
비슷한 방식을 찾아보던 중, Open Domain Question Answering 과 Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks 논문을 보고 Retrieval 을 통해 어떠한 키워드 및 주제에 유사도가 높은 데이터만을 학습시키면 해당 주제에서 기가막히는 글을 생성해 낼 것이다는 아이디어를 떠올리게 되었습니다. 하나의 모델에서 한 번에 긴 글을 생성해내는 것보다는, 각각의 주제에 professional 한 작가모델을 여러 개 생성해내고 그 모델들로 생성해낸 결과를 조합하는 방식입니다. 이러한 방식으로 주제와 Prompt만 잘 선정한다면 Supervised 하게 저희가 쓰고자 하는 내용을 쉽게 유도할 수 있을 것이라고 생각하였으며 일관성 면에서도 하나의 모델을 사용하는 것보다 좋은 결과가 있을 것이란 예상을 하게 되었습니다.
주제 선정
주제에 대한 Retrieval 을 진행하기 위해서는 우선 저희가 쓰고자 하는 글의 주제를 선정할 필요가 있었습니다. 제 3회 AI x Bookathon 의 주제는 함께 였습니다. 해당 주제를 듣고 수많은 아이스 브레이킹을 하며 어떤 주제를 통해 글을 써내려가는 것이 좋을지에 대해 굉장히 많은 고민을 했습니다.
최종 주제의 아이디어는 미하일 바흐친 의 대화이론 철학으로부터 얻게 되었습니다. 바흐친은 다양한 관념과 목소리들이 어떠한 인식적 토대를 통해 조화로운 전체를 형성해 나가는 과정을 대화이론 으로 소개합니다. 대화이론의 핵심은 나 와 자아 에서 떠도는 단성악적 목소리들로부터 점점 의식과 관념의 다양성을 인식하며 다성악적인 전체를 나 와 타자 의 관계를 통해서 형성한다는 것입니다. 저희는 이 대화주의 철학에 공감하며 불특정한 개인이 함께 이지 않음에서 얻게되는 괴로움과 고뇌로부터 찰나의 순간 나 와 나 의 관계, 그리고 나 와 타자 의 관계성을 인식하며 추억과 행복감을 느끼는 스토리라인을 구성하게 되었습니다. 다만 이러한 철학과 감정 중심의 글은 너무 abstract 할 수 있다는 판단이 들었고, 최종적으로 만들어야 하는 글은 수필의 형태였기 때문에 긴장감을 조성하기 위한 사건, 함께라는 주제에 어울리는 교훈을 내포하기 위하여 소주제와 제목을 선정하게 되었습니다. 그렇게 선정된 내역은 아래와 같습니다.

저희는 이와같이 소주제를 선정하였고, 각각의 소주제에 해당하는 문장들을 Query 로 하여 Retrieval 을 진행하기로 하였습니다.
Retrieval

Open Domain Question Answering 과제에서는 Query 가 들어오면 Wiipedia 에서 주어진 쿼리와 유사한 Passage 들을 가져오는 Retrieval 시스템이 존재합니다. 이와 유사하게 저희의 소주제를 쿼리로 하여 수집한 약 3만 건의 데이터에서 유사도가 높은 문장들을 가져오는 Retrieval 을 구현하게 되었습니다. TF-IDF, Dense Passage Retrieval 등 다양한 방법이 많았지만 저희는 bm25 를 사용한 Elastic Search 를 사용하게 되었습니다.
Elastic Search 는 오픈소스 검색엔진으로 빠른 속도로 방대한 양의 문서를 검색할 수 있습니다. BM25 scoring 알고리즘과 Nori Tokenizer 를 사용하여 저희가 수집한 데이터의 Sparse Embedding 을 만들어냈고 쿼리와의 유사도를 기반으로 관련 주제에 걸맞는 알맞은 Text 를 불러오게 하였습니다.
하지만 Retrieval 에 Pilot Test 를 진행하고 정성적으로 평가하였을 때 생각보다 의미에 매칭되는 텍스트가 별로 없었습니다. 이것의 원인으로는 Sparse Embedding 의 특성상 단어의 빈도, 문장 길이 등을 고려하기 때문에 저희의 소주제와 의미적으로 유사한 텍스트를 가져오지 못한다는 것을 에상할 수 있었습니다. 따라서 저희는 소주제를 대표하는 Keyword 를 일일이 뽑아내었고, 그 중에서 총 7개의 Query 를 만들어낼 수 있었습니다. 7개의 쿼리는 아래와 같습니다.
- 함께라는 것은
- 희망과 함께
- 우울과 함께
- 불안과 함께
- 죽음과 공존
- 자아와 함께
- 행복한 추억
이 때 전체 주제인 ‘함께’ 를 결합하여 주제에 벗어나지 않는 텍스트 중에서만 유사도를 고려할 수 있게 하였습니다.
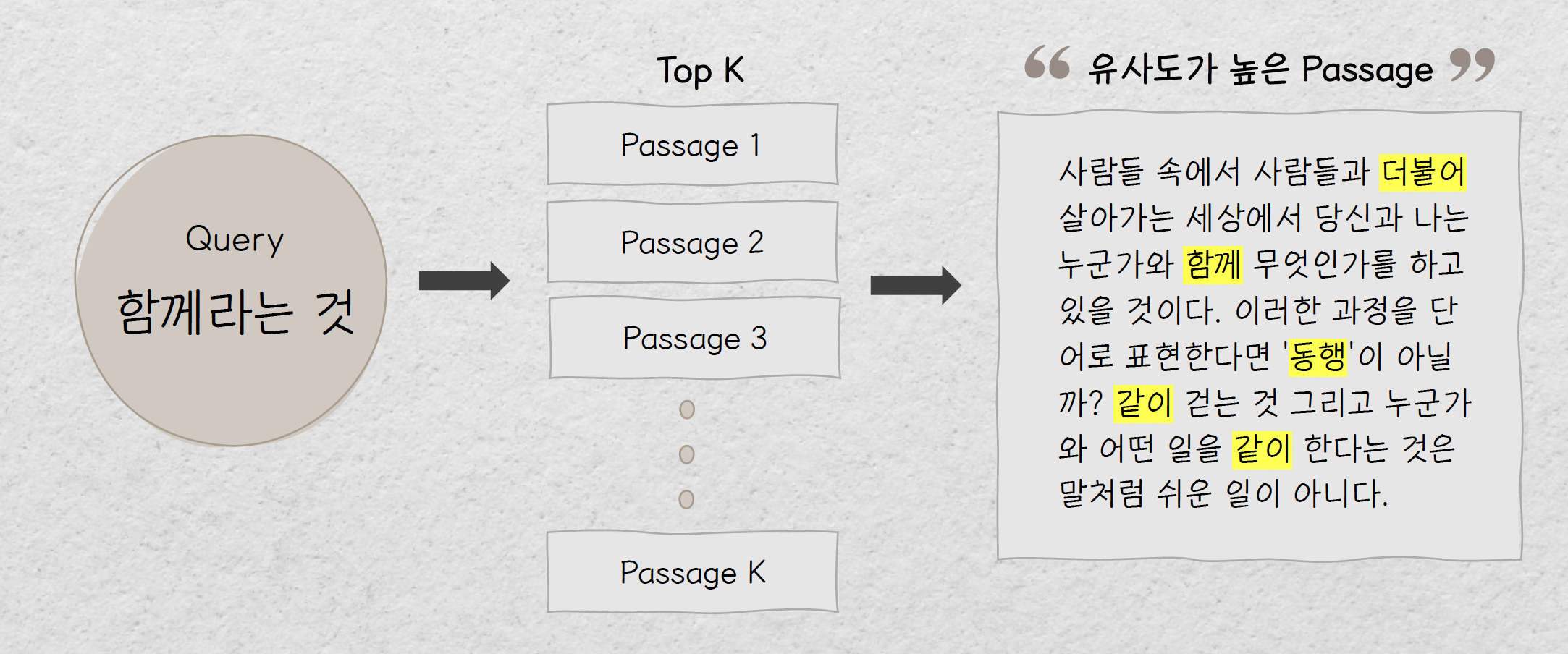
이렇게 각각의 쿼리에 대하여 500개의 데이터 샘플들을 모을 수 있었습니다.
모델 선정 및 학습
저희가 최종적으로 사용한 모델은 skt/ko-gpt-trinity-1.2B-v0.5 입니다. 시중에 공개되어 있는 사전학습 생성모델 중 가장 많은 parameter 를 가지고 있으며,

GPT-3 논문에서 소개하듯이 Parameter 의 개수가 모델 성능으로 이어진다는 것에서 영감을 받아 최대한 큰 모델을 사용하고자 했습니다.
또한 MindsLab 에서 제공해준 모델과의 benchmark 를 직접적으로 확인할 수가 없어서 pilot test를 정성적으로 진행했을 때

ko-gpt-trinity 를 사용하는 것이 더 일관된 문장을 생성할 수 있겠다고 판단하게 되었습니다.
하지만, T4 의 한계는 여전히 남아있었습니다. Batch size 를 1로 하여도 항상 out-of-memory 문제가 발생하였습니다. 때문에 저희는

24개의 Decoder Layer 중 12개의 Decoder Layer 를 Freezing 시키고, Half Precision 을 사용함으로써 겨우 학습을 진행할 수 있었습니다. 또한 batch 크기를 최소한으로 했기 때문에 Accumulation step 을 활용하였습니다.
이렇게 각각의 Keyword 에 대해 Retrieval 로 가져온 500개의 Sample 들을 Fine-tuning 시켜서 총 7개의 수필작가 모델을 만들어낼 수 있었습니다.
수필 생성
위에서 만들어낸 7개의 수필작가 모델로 하여금 글을 생성하게 했을 때 Prompt 로 주어지는 텍스트, 그리고 generate method 의 argument 에 따라서 매우 다른 결과들이 생성되었습니다.

또한 Beam search 를 사용했을 때 Repetition Problem 이 발생했기 때문에

Top-P Sampling 방식을 사용하여 Generate 를 진행했습니다. 이 때 사용한 코드는 아래와 같습니다.
1 | gen_ids = model.generate(torch.tensor([input_ids]), |
하지만 Max Length 를 길게 잡았을 때 여전히 생성된 텍스트에 일관성이 존재하지 않는 현상이 발생하였습니다. 따라서 호흡을 짧게 가져가며 문장을 생성하였고, 생성된 문장을 다음 입력의 문장으로 하여 자연스러운 문맥을 이어갈 수 있도록 처리하였습니다.
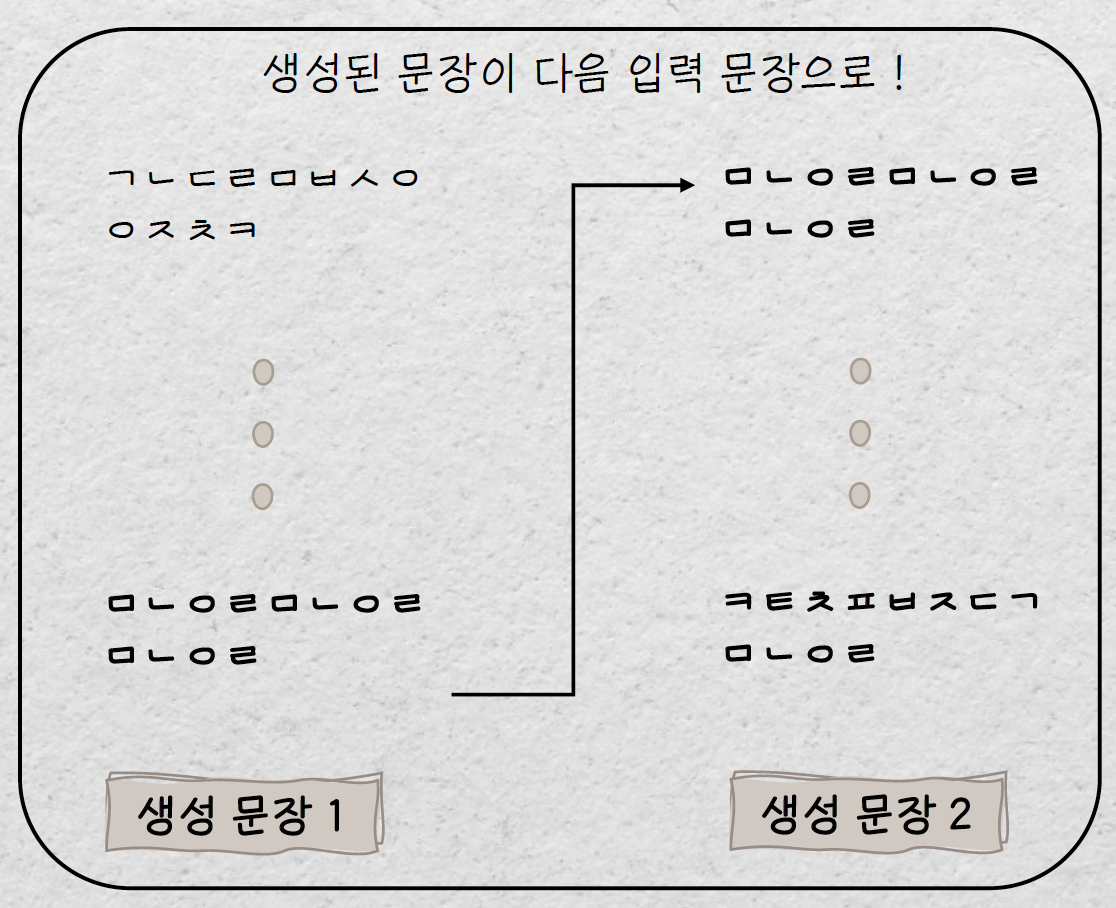
이 때 생성된 문장을 length 단위로 계산하기 때문에 문장이 중간에 끊겨버리는 경우를 방지하기 위하여 문단 단위로 글을 생성하도록 하였습니다. 그렇게 사용한 최종 생성 코드는 아래와 같습니다.
1 | total = list(range(3000)) |
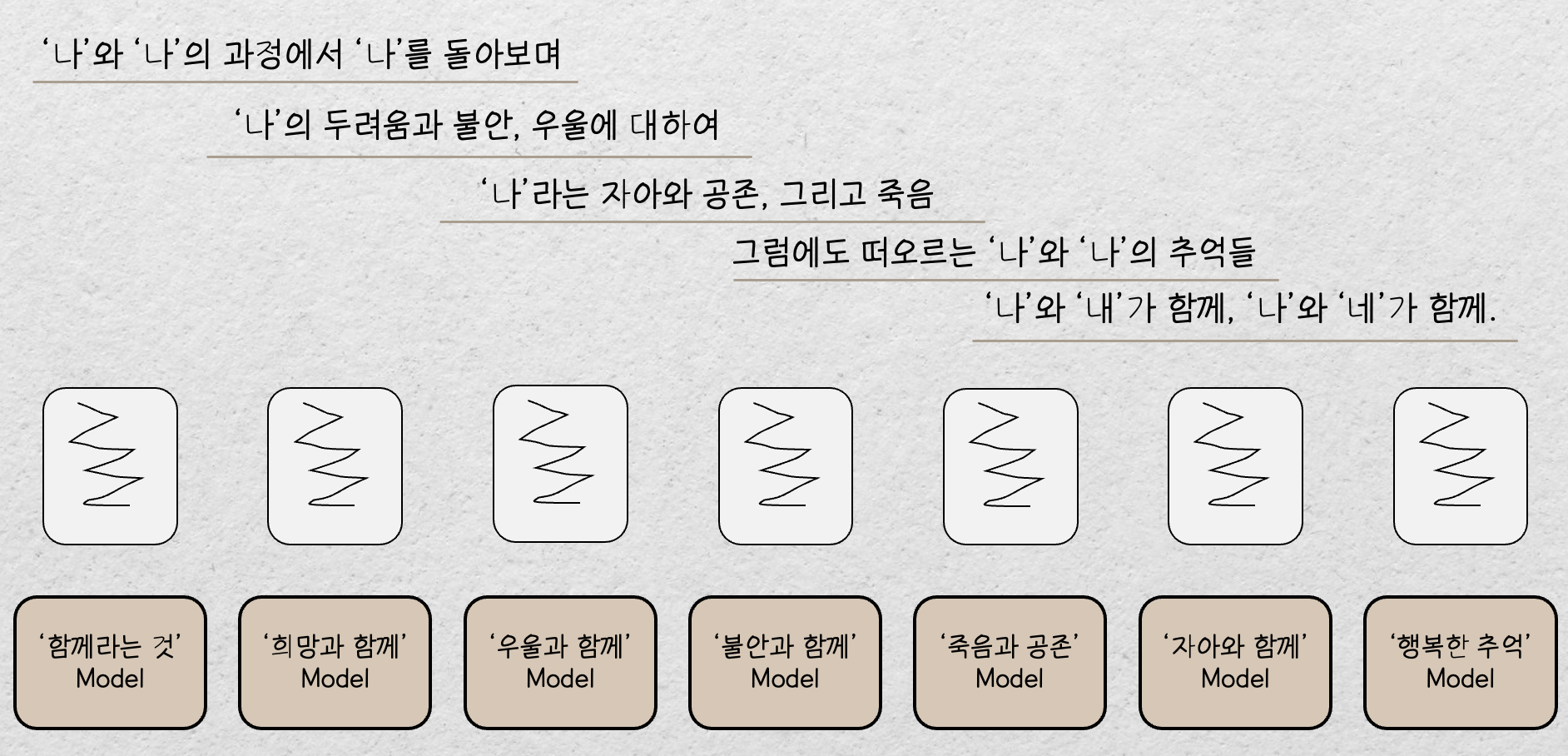
그렇게 위와 같은 방식으로 7개의 수필작가 모델로 하여금 소주제에 해당하는 글을 작성하게 함으로써 보다 자연스럽게 이어지는 작품을 만들어낼 수 있었습니다.
최종 작품은 이곳에서 보실 수 있습니다.
마지막으로
이렇게 무박 2일동안 진행되었던 프로젝트를 무사히 마칠 수 있었습니다.
부족한 점도 많고, 아쉬운 점도 많았지만 짧은 시간안에 다른 팀들과 차별화된 방법론으로 매우 가치있는 작품을 생성해낼 수 있어서 굉장히 좋은 경험이었다고 생각합니다.
이러한 대회를 제공해주신 성균관대학교와, 마인즈랩, 그리고 네이버 클로바팀에게 감사의 인사를 드리며 마치겠습니다.
감사합니다.
AI Bookathon 대상 후기